本文基于kubernetes v1.21
概述
kube-scheduller是k8s的核心组件之一,负责为pod选择最优node kube-scheduller的优选过程是给所有通过filter流程的node打分,然后把结果传给后续流程
架构分析
A picture is worth a thousand words(从别人的博客里偷来的图)
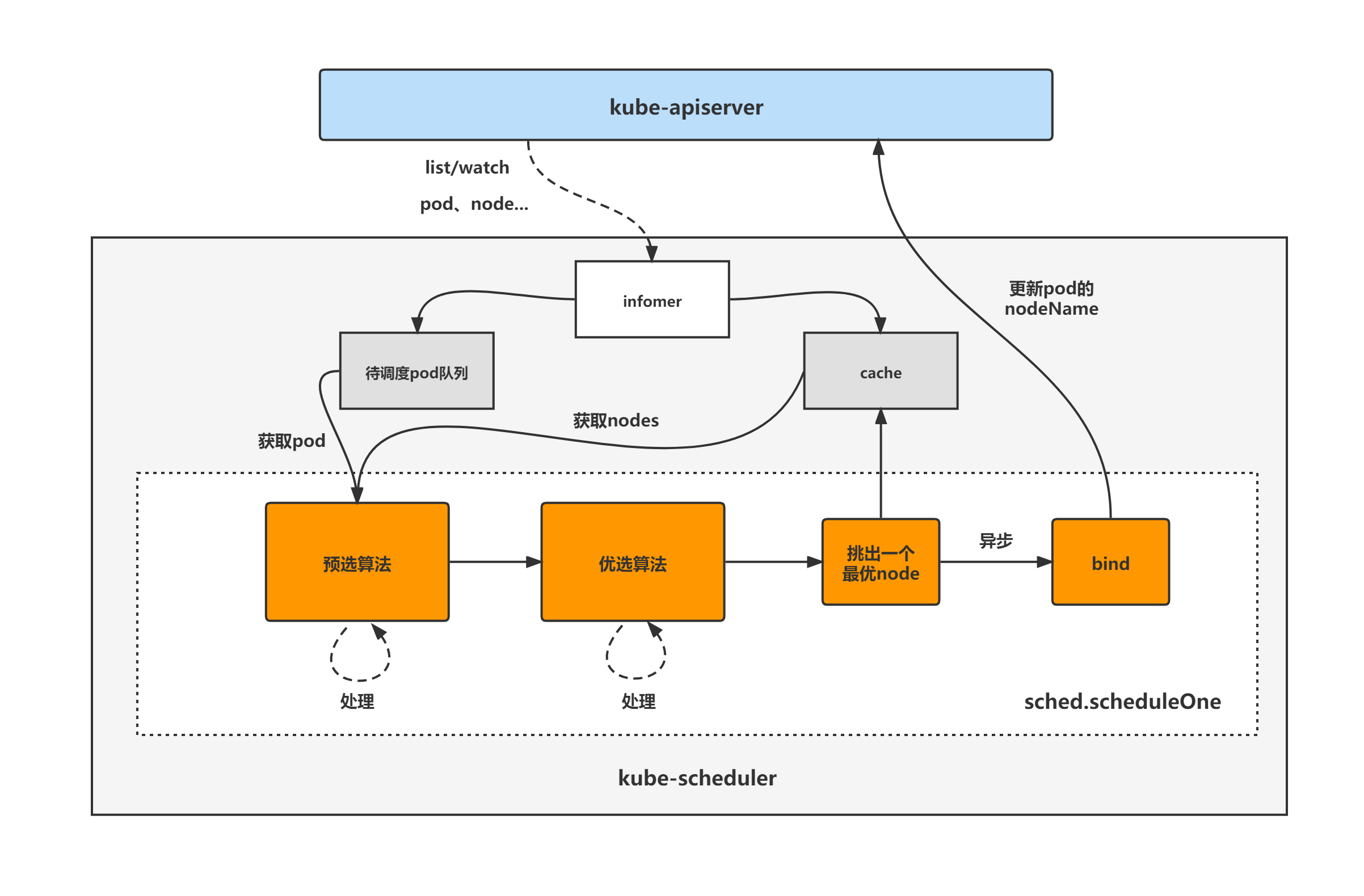
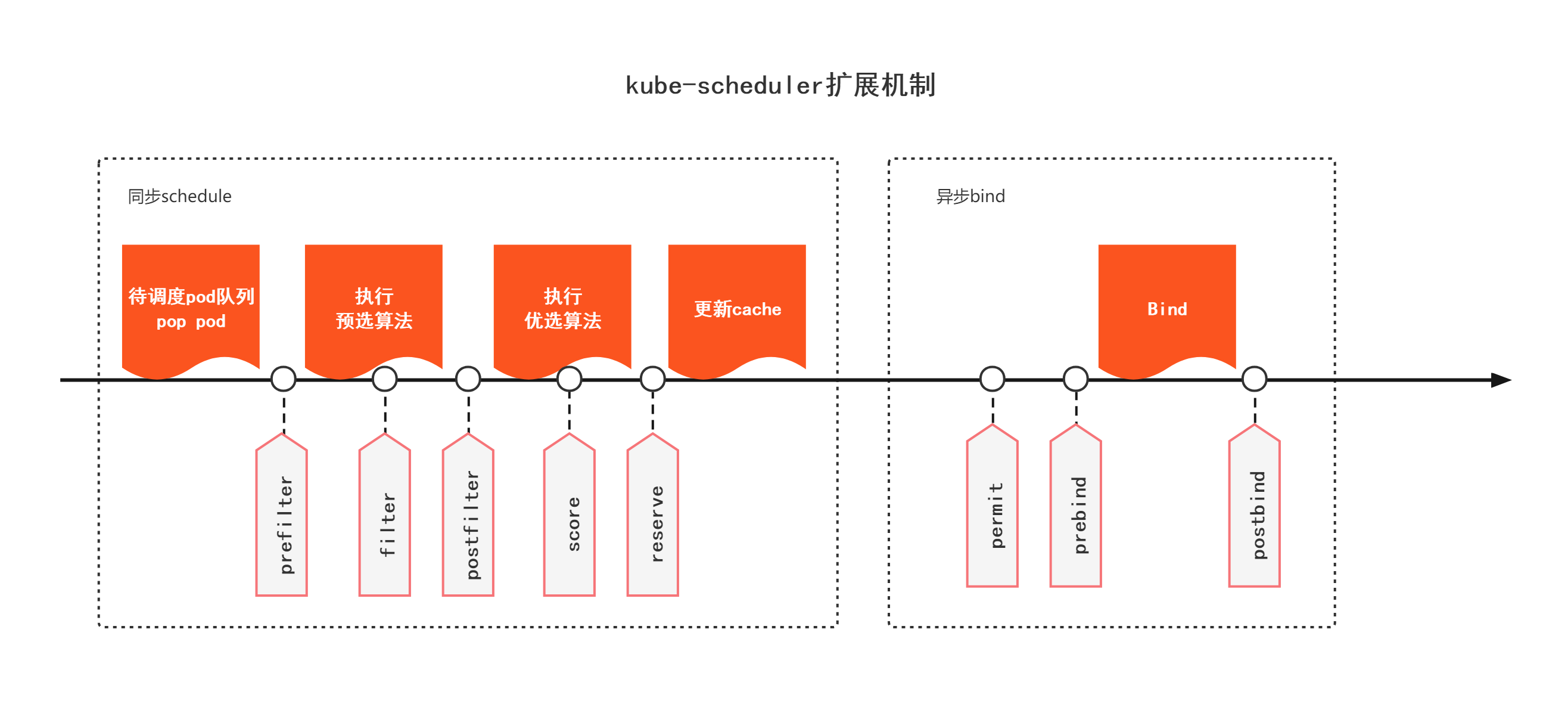
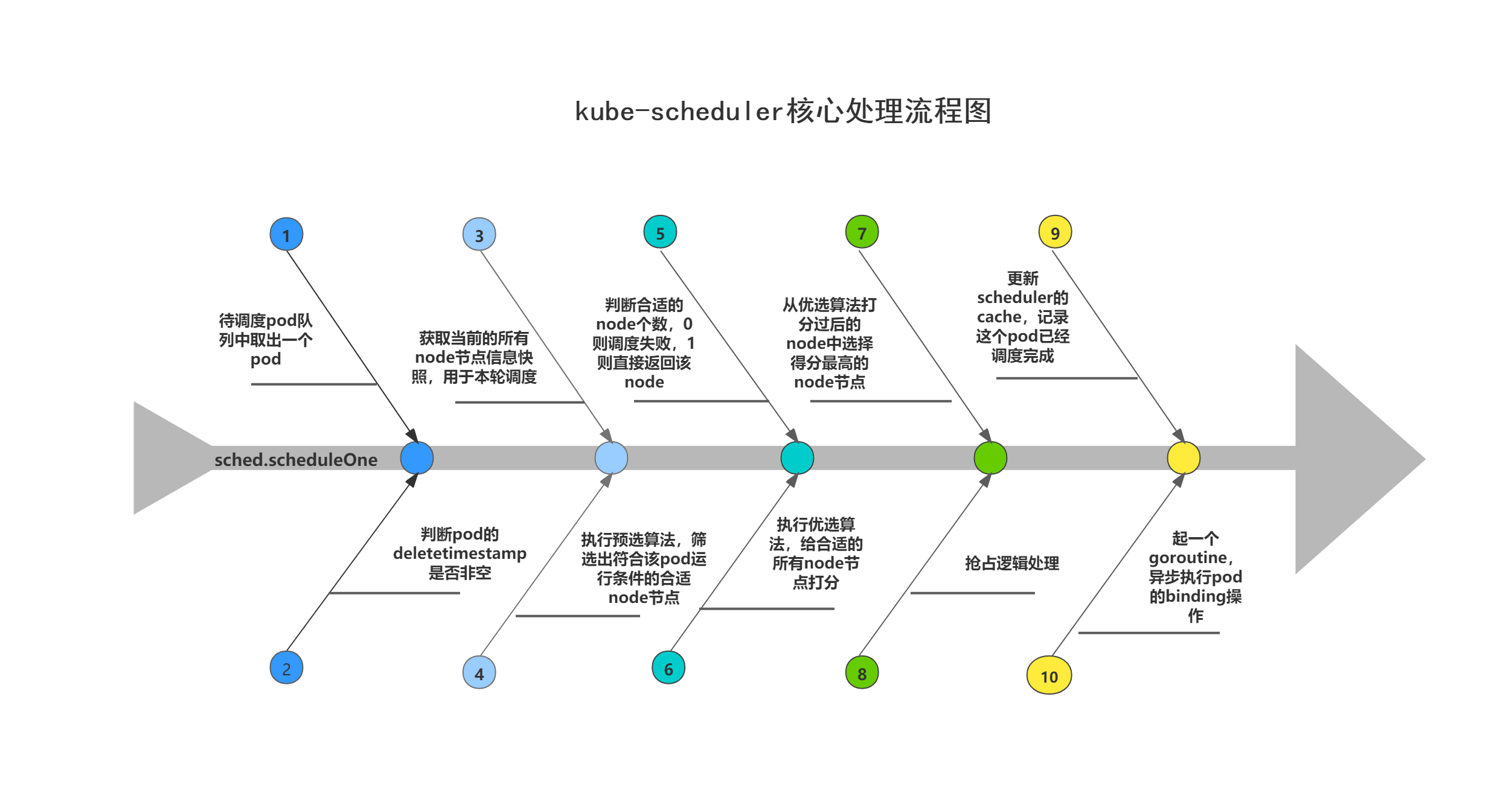
流程分析
调用栈
main() cmd/kube-scheduler/scheduler.go
|
func NewSchedulerCommand() cmd/kube-scheduler/app/server.go
|
func runCommand(
*cobra.Command,
*options.Options,
...Option
) cmd/kube-scheduler/app/server.go
|
func Run(
context.Context,
*schedulerserverconfig.CompletedConfig,
*scheduler.Scheduler
) cmd/kube-scheduler/app/server.go
|
LeaderElector cmd/kube-scheduler/app/server.go
|
func (sched *Scheduler) Run(context.Context) pkg/scheduler/scheduler.go
|
func (sched *Scheduler) scheduleOne(context.Context) pkg/scheduler/scheduler.go
|
func (g *genericScheduler) Schedule(
context.Context,
framework.Framework,
*framework.CycleState,
*v1.Pod
) (ScheduleResult,error) pkg/scheduler/core/generic_scheduler.go
|
func (g *genericScheduler) prioritizeNodes(
ctx context.Context,
fwk framework.Framework,
state *framework.CycleState,
pod *v1.Pod,
nodes []*v1.Node,
) (framework.NodeScoreList, error) pkg/scheduler/core/generic_scheduler.go
优选过程
prioritizeNodes函数
- 先判断是否存在Score插件和扩展,如果没有则返回节点的分数都为1
- PreScore插件
- Score插件
pkg/scheduler/core/generic_scheduler.go
// prioritizeNodes prioritizes the nodes by running the score plugins,
// which return a score for each node from the call to RunScorePlugins().
// The scores from each plugin are added together to make the score for that node, then
// any extenders are run as well.
// All scores are finally combined (added) to get the total weighted scores of all nodes
func (g *genericScheduler) prioritizeNodes(
ctx context.Context,
fwk framework.Framework,
state *framework.CycleState,
pod *v1.Pod,
nodes []*v1.Node,
) (framework.NodeScoreList, error) {
// If no priority configs are provided, then all nodes will have a score of one.
// This is required to generate the priority list in the required format
if len(g.extenders) == 0 && !fwk.HasScorePlugins() {
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes {
result = append(result, framework.NodeScore{
Name: nodes[i].Name,
Score: 1,
})
}
return result, nil
}
// Run PreScore plugins.
preScoreStatus := fwk.RunPreScorePlugins(ctx, state, pod, nodes)
if !preScoreStatus.IsSuccess() {
return nil, preScoreStatus.AsError()
}
// Run the Score plugins.
scoresMap, scoreStatus := fwk.RunScorePlugins(ctx, state, pod, nodes)
if !scoreStatus.IsSuccess() {
return nil, scoreStatus.AsError()
}
if klog.V(10).Enabled() {
for plugin, nodeScoreList := range scoresMap {
for _, nodeScore := range nodeScoreList {
klog.InfoS("Plugin scored node for pod", "pod", klog.KObj(pod), "plugin", plugin, "node", nodeScore.Name, "score", nodeScore.Score)
}
}
}
// Summarize all scores.
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes {
result = append(result, framework.NodeScore{Name: nodes[i].Name, Score: 0})
for j := range scoresMap {
result[i].Score += scoresMap[j][i].Score
}
}
if len(g.extenders) != 0 && nodes != nil {
var mu sync.Mutex
var wg sync.WaitGroup
combinedScores := make(map[string]int64, len(nodes))
for i := range g.extenders {
if !g.extenders[i].IsInterested(pod) {
continue
}
wg.Add(1)
go func(extIndex int) {
metrics.SchedulerGoroutines.WithLabelValues(metrics.PrioritizingExtender).Inc()
defer func() {
metrics.SchedulerGoroutines.WithLabelValues(metrics.PrioritizingExtender).Dec()
wg.Done()
}()
prioritizedList, weight, err := g.extenders[extIndex].Prioritize(pod, nodes)
if err != nil {
// Prioritization errors from extender can be ignored, let k8s/other extenders determine the priorities
return
}
mu.Lock()
for i := range *prioritizedList {
host, score := (*prioritizedList)[i].Host, (*prioritizedList)[i].Score
if klog.V(10).Enabled() {
klog.InfoS("Extender scored node for pod", "pod", klog.KObj(pod), "extender", g.extenders[extIndex].Name(), "node", host, "score", score)
}
combinedScores[host] += score * weight
}
mu.Unlock()
}(i)
}
// wait for all go routines to finish
wg.Wait()
for i := range result {
// MaxExtenderPriority may diverge from the max priority used in the scheduler and defined by MaxNodeScore,
// therefore we need to scale the score returned by extenders to the score range used by the scheduler.
result[i].Score += combinedScores[result[i].Name] * (framework.MaxNodeScore / extenderv1.MaxExtenderPriority)
}
}
if klog.V(10).Enabled() {
for i := range result {
klog.InfoS("Calculated node's final score for pod", "pod", klog.KObj(pod), "node", result[i].Name, "score", result[i].Score)
}
}
return result, nil
}
RunPreScorePlugins函数
顺序执行PreScore插件
pkg/scheduler/framework/runtime/framework.go
// RunPreScorePlugins runs the set of configured pre-score plugins. If any
// of these plugins returns any status other than "Success", the given pod is rejected.
func (f *frameworkImpl) RunPreScorePlugins(
ctx context.Context,
state *framework.CycleState,
pod *v1.Pod,
nodes []*v1.Node,
) (status *framework.Status) {
startTime := time.Now()
defer func() {
metrics.FrameworkExtensionPointDuration.WithLabelValues(preScore, status.Code().String(), f.profileName).Observe(metrics.SinceInSeconds(startTime))
}()
for _, pl := range f.preScorePlugins {
status = f.runPreScorePlugin(ctx, pl, state, pod, nodes)
if !status.IsSuccess() {
return framework.AsStatus(fmt.Errorf("running PreScore plugin %q: %w", pl.Name(), status.AsError()))
}
}
return nil
}
func (f *frameworkImpl) runPreScorePlugin(ctx context.Context, pl framework.PreScorePlugin, state *framework.CycleState, pod *v1.Pod, nodes []*v1.Node) *framework.Status {
if !state.ShouldRecordPluginMetrics() {
return pl.PreScore(ctx, state, pod, nodes)
}
startTime := time.Now()
status := pl.PreScore(ctx, state, pod, nodes)
f.metricsRecorder.observePluginDurationAsync(preScore, pl.Name(), status, metrics.SinceInSeconds(startTime))
return status
}
RunScorePlugins函数
运行节点数个goroutine为每个filter后的节点按照Score插件顺序打分
pkg/scheduler/framework/runtime/framework.go
// RunScorePlugins runs the set of configured scoring plugins. It returns a list that
// stores for each scoring plugin name the corresponding NodeScoreList(s).
// It also returns *Status, which is set to non-success if any of the plugins returns
// a non-success status.
func (f *frameworkImpl) RunScorePlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodes []*v1.Node) (ps framework.PluginToNodeScores, status *framework.Status) {
startTime := time.Now()
defer func() {
metrics.FrameworkExtensionPointDuration.WithLabelValues(score, status.Code().String(), f.profileName).Observe(metrics.SinceInSeconds(startTime))
}()
pluginToNodeScores := make(framework.PluginToNodeScores, len(f.scorePlugins))
for _, pl := range f.scorePlugins {
pluginToNodeScores[pl.Name()] = make(framework.NodeScoreList, len(nodes))
}
ctx, cancel := context.WithCancel(ctx)
errCh := parallelize.NewErrorChannel()
// Run Score method for each node in parallel.
f.Parallelizer().Until(ctx, len(nodes), func(index int) {
for _, pl := range f.scorePlugins {
nodeName := nodes[index].Name
s, status := f.runScorePlugin(ctx, pl, state, pod, nodeName)
if !status.IsSuccess() {
err := fmt.Errorf("plugin %q failed with: %w", pl.Name(), status.AsError())
errCh.SendErrorWithCancel(err, cancel)
return
}
pluginToNodeScores[pl.Name()][index] = framework.NodeScore{
Name: nodeName,
Score: s,
}
}
})
if err := errCh.ReceiveError(); err != nil {
return nil, framework.AsStatus(fmt.Errorf("running Score plugins: %w", err))
}
// Run NormalizeScore method for each ScorePlugin in parallel.
f.Parallelizer().Until(ctx, len(f.scorePlugins), func(index int) {
pl := f.scorePlugins[index]
nodeScoreList := pluginToNodeScores[pl.Name()]
if pl.ScoreExtensions() == nil {
return
}
status := f.runScoreExtension(ctx, pl, state, pod, nodeScoreList)
if !status.IsSuccess() {
err := fmt.Errorf("plugin %q failed with: %w", pl.Name(), status.AsError())
errCh.SendErrorWithCancel(err, cancel)
return
}
})
if err := errCh.ReceiveError(); err != nil {
return nil, framework.AsStatus(fmt.Errorf("running Normalize on Score plugins: %w", err))
}
// Apply score defaultWeights for each ScorePlugin in parallel.
f.Parallelizer().Until(ctx, len(f.scorePlugins), func(index int) {
pl := f.scorePlugins[index]
// Score plugins' weight has been checked when they are initialized.
weight := f.pluginNameToWeightMap[pl.Name()]
nodeScoreList := pluginToNodeScores[pl.Name()]
for i, nodeScore := range nodeScoreList {
// return error if score plugin returns invalid score.
if nodeScore.Score > framework.MaxNodeScore || nodeScore.Score < framework.MinNodeScore {
err := fmt.Errorf("plugin %q returns an invalid score %v, it should in the range of [%v, %v] after normalizing", pl.Name(), nodeScore.Score, framework.MinNodeScore, framework.MaxNodeScore)
errCh.SendErrorWithCancel(err, cancel)
return
}
nodeScoreList[i].Score = nodeScore.Score * int64(weight)
}
})
if err := errCh.ReceiveError(); err != nil {
return nil, framework.AsStatus(fmt.Errorf("applying score defaultWeights on Score plugins: %w", err))
}
return pluginToNodeScores, nil
}
func (f *frameworkImpl) runScorePlugin(ctx context.Context, pl framework.ScorePlugin, state *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
if !state.ShouldRecordPluginMetrics() {
return pl.Score(ctx, state, pod, nodeName)
}
startTime := time.Now()
s, status := pl.Score(ctx, state, pod, nodeName)
f.metricsRecorder.observePluginDurationAsync(score, pl.Name(), status, metrics.SinceInSeconds(startTime))
return s, status
}
func (f *frameworkImpl) runScoreExtension(ctx context.Context, pl framework.ScorePlugin, state *framework.CycleState, pod *v1.Pod, nodeScoreList framework.NodeScoreList) *framework.Status {
if !state.ShouldRecordPluginMetrics() {
return pl.ScoreExtensions().NormalizeScore(ctx, state, pod, nodeScoreList)
}
startTime := time.Now()
status := pl.ScoreExtensions().NormalizeScore(ctx, state, pod, nodeScoreList)
f.metricsRecorder.observePluginDurationAsync(scoreExtensionNormalize, pl.Name(), status, metrics.SinceInSeconds(startTime))
return status
}
默认启用的插件
PreScore: schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: interpodaffinity.Name},
{Name: podtopologyspread.Name},
{Name: tainttoleration.Name},
{Name: nodeaffinity.Name},
},
},
Score: schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: noderesources.BalancedAllocationName, Weight: 1},
{Name: imagelocality.Name, Weight: 1},
{Name: interpodaffinity.Name, Weight: 1},
{Name: noderesources.LeastAllocatedName, Weight: 1},
{Name: nodeaffinity.Name, Weight: 1},
{Name: nodepreferavoidpods.Name, Weight: 10000},
// Weight is doubled because:
// - This is a score coming from user preference.
// - It makes its signal comparable to NodeResourcesLeastAllocated.
{Name: podtopologyspread.Name, Weight: 2},
{Name: tainttoleration.Name, Weight: 1},
},
},
PodTopologySpread(Pod拓扑分布约束)
PreScore
interpodaffinity
- 获取pod.Spec.Affinity
- 如果有pod.Spec.Affinity则获取所有节点列表,否则获取HavePodsWithAffinityList节点列表
- 运行节点数个goroutine去为每一个node打分 顺序遍历节点上的存在的Pod,根据调度pod的trem和节点上存在pod的term为节点打分
pkg/scheduler/framework/plugins/interpodaffinity/scoring.go
// PreScore builds and writes cycle state used by Score and NormalizeScore.
func (pl *InterPodAffinity) PreScore(
pCtx context.Context,
cycleState *framework.CycleState,
pod *v1.Pod,
nodes []*v1.Node,
) *framework.Status {
if len(nodes) == 0 {
// No nodes to score.
return nil
}
if pl.sharedLister == nil {
return framework.NewStatus(framework.Error, "empty shared lister in InterPodAffinity PreScore")
}
affinity := pod.Spec.Affinity
hasPreferredAffinityConstraints := affinity != nil && affinity.PodAffinity != nil && len(affinity.PodAffinity.PreferredDuringSchedulingIgnoredDuringExecution) > 0
hasPreferredAntiAffinityConstraints := affinity != nil && affinity.PodAntiAffinity != nil && len(affinity.PodAntiAffinity.PreferredDuringSchedulingIgnoredDuringExecution) > 0
// Unless the pod being scheduled has preferred affinity terms, we only
// need to process nodes hosting pods with affinity.
var allNodes []*framework.NodeInfo
var err error
if hasPreferredAffinityConstraints || hasPreferredAntiAffinityConstraints {
allNodes, err = pl.sharedLister.NodeInfos().List()
if err != nil {
framework.AsStatus(fmt.Errorf("failed to get all nodes from shared lister: %w", err))
}
} else {
allNodes, err = pl.sharedLister.NodeInfos().HavePodsWithAffinityList()
if err != nil {
framework.AsStatus(fmt.Errorf("failed to get pods with affinity list: %w", err))
}
}
state := &preScoreState{
topologyScore: make(map[string]map[string]int64),
}
state.podInfo = framework.NewPodInfo(pod)
if state.podInfo.ParseError != nil {
// Ideally we never reach here, because errors will be caught by PreFilter
return framework.AsStatus(fmt.Errorf("failed to parse pod: %w", state.podInfo.ParseError))
}
if pl.enableNamespaceSelector {
for i := range state.podInfo.PreferredAffinityTerms {
if err := pl.mergeAffinityTermNamespacesIfNotEmpty(&state.podInfo.PreferredAffinityTerms[i].AffinityTerm); err != nil {
return framework.AsStatus(fmt.Errorf("updating PreferredAffinityTerms: %w", err))
}
}
for i := range state.podInfo.PreferredAntiAffinityTerms {
if err := pl.mergeAffinityTermNamespacesIfNotEmpty(&state.podInfo.PreferredAntiAffinityTerms[i].AffinityTerm); err != nil {
return framework.AsStatus(fmt.Errorf("updating PreferredAntiAffinityTerms: %w", err))
}
}
state.namespaceLabels = GetNamespaceLabelsSnapshot(pod.Namespace, pl.nsLister)
}
topoScores := make([]scoreMap, len(allNodes))
index := int32(-1)
processNode := func(i int) {
nodeInfo := allNodes[i]
if nodeInfo.Node() == nil {
return
}
// Unless the pod being scheduled has preferred affinity terms, we only
// need to process pods with affinity in the node.
podsToProcess := nodeInfo.PodsWithAffinity
if hasPreferredAffinityConstraints || hasPreferredAntiAffinityConstraints {
// We need to process all the pods.
podsToProcess = nodeInfo.Pods
}
topoScore := make(scoreMap)
for _, existingPod := range podsToProcess {
pl.processExistingPod(state, existingPod, nodeInfo, pod, topoScore)
}
if len(topoScore) > 0 {
topoScores[atomic.AddInt32(&index, 1)] = topoScore
}
}
pl.parallelizer.Until(context.Background(), len(allNodes), processNode)
for i := 0; i <= int(index); i++ {
state.topologyScore.append(topoScores[i])
}
cycleState.Write(preScoreStateKey, state)
return nil
}
func (pl *InterPodAffinity) processExistingPod(
state *preScoreState,
existingPod *framework.PodInfo,
existingPodNodeInfo *framework.NodeInfo,
incomingPod *v1.Pod,
topoScore scoreMap,
) {
existingPodNode := existingPodNodeInfo.Node()
if len(existingPodNode.Labels) == 0 {
return
}
// For every soft pod affinity term of <pod>, if <existingPod> matches the term,
// increment <p.counts> for every node in the cluster with the same <term.TopologyKey>
// value as that of <existingPods>`s node by the term`s weight.
// Note that the incoming pod's terms have the namespaceSelector merged into the namespaces, and so
// here we don't lookup the existing pod's namespace labels, hence passing nil for nsLabels.
topoScore.processTerms(state.podInfo.PreferredAffinityTerms, existingPod.Pod, nil, existingPodNode, 1, pl.enableNamespaceSelector)
// For every soft pod anti-affinity term of <pod>, if <existingPod> matches the term,
// decrement <p.counts> for every node in the cluster with the same <term.TopologyKey>
// value as that of <existingPod>`s node by the term`s weight.
// Note that the incoming pod's terms have the namespaceSelector merged into the namespaces, and so
// here we don't lookup the existing pod's namespace labels, hence passing nil for nsLabels.
topoScore.processTerms(state.podInfo.PreferredAntiAffinityTerms, existingPod.Pod, nil, existingPodNode, -1, pl.enableNamespaceSelector)
// For every hard pod affinity term of <existingPod>, if <pod> matches the term,
// increment <p.counts> for every node in the cluster with the same <term.TopologyKey>
// value as that of <existingPod>'s node by the constant <args.hardPodAffinityWeight>
if pl.args.HardPodAffinityWeight > 0 && len(existingPodNode.Labels) != 0 {
for _, t := range existingPod.RequiredAffinityTerms {
topoScore.processTerm(&t, pl.args.HardPodAffinityWeight, incomingPod, state.namespaceLabels, existingPodNode, 1, pl.enableNamespaceSelector)
}
}
// For every soft pod affinity term of <existingPod>, if <pod> matches the term,
// increment <p.counts> for every node in the cluster with the same <term.TopologyKey>
// value as that of <existingPod>'s node by the term's weight.
topoScore.processTerms(existingPod.PreferredAffinityTerms, incomingPod, state.namespaceLabels, existingPodNode, 1, pl.enableNamespaceSelector)
// For every soft pod anti-affinity term of <existingPod>, if <pod> matches the term,
// decrement <pm.counts> for every node in the cluster with the same <term.TopologyKey>
// value as that of <existingPod>'s node by the term's weight.
topoScore.processTerms(existingPod.PreferredAntiAffinityTerms, incomingPod, state.namespaceLabels, existingPodNode, -1, pl.enableNamespaceSelector)
}
func (m scoreMap) processTerms(terms []framework.WeightedAffinityTerm, pod *v1.Pod, nsLabels labels.Set, node *v1.Node, multiplier int32, enableNamespaceSelector bool) {
for _, term := range terms {
m.processTerm(&term.AffinityTerm, term.Weight, pod, nsLabels, node, multiplier, enableNamespaceSelector)
}
}
func (m scoreMap) processTerm(term *framework.AffinityTerm, weight int32, pod *v1.Pod, nsLabels labels.Set, node *v1.Node, multiplier int32, enableNamespaceSelector bool) {
if term.Matches(pod, nsLabels, enableNamespaceSelector) {
if tpValue, tpValueExist := node.Labels[term.TopologyKey]; tpValueExist {
if m[term.TopologyKey] == nil {
m[term.TopologyKey] = make(map[string]int64)
}
m[term.TopologyKey][tpValue] += int64(weight * multiplier)
}
}
}
PodTopologySpread
- 获取所有节点
- initPreScoreState函数 a. 设置s.Constraints为pod.Spec.TopologySpreadConstraints(没有pod.Spec则设置默认Constraints) b. 遍历filteredNodes,设置s.IgnoredNodes和s.TopologyPairToPodCounts c. 遍历s.Constraints设置s.TopologyNormalizingWeight
- 运行节点数个goroutine去为每一个node打分 如果节点不符合pod的NodeAffinity,直接返回 顺序遍历state.Constraints,根据pod的lable计算count
// PreScore builds and writes cycle state used by Score and NormalizeScore.
func (pl *PodTopologySpread) PreScore(
ctx context.Context,
cycleState *framework.CycleState,
pod *v1.Pod,
filteredNodes []*v1.Node,
) *framework.Status {
allNodes, err := pl.sharedLister.NodeInfos().List()
if err != nil {
return framework.AsStatus(fmt.Errorf("getting all nodes: %w", err))
}
if len(filteredNodes) == 0 || len(allNodes) == 0 {
// No nodes to score.
return nil
}
state := &preScoreState{
IgnoredNodes: sets.NewString(),
TopologyPairToPodCounts: make(map[topologyPair]*int64),
}
err = pl.initPreScoreState(state, pod, filteredNodes)
if err != nil {
return framework.AsStatus(fmt.Errorf("calculating preScoreState: %w", err))
}
// return if incoming pod doesn't have soft topology spread Constraints.
if len(state.Constraints) == 0 {
cycleState.Write(preScoreStateKey, state)
return nil
}
// Ignore parsing errors for backwards compatibility.
requiredNodeAffinity := nodeaffinity.GetRequiredNodeAffinity(pod)
processAllNode := func(i int) {
nodeInfo := allNodes[i]
node := nodeInfo.Node()
if node == nil {
return
}
// (1) `node` should satisfy incoming pod's NodeSelector/NodeAffinity
// (2) All topologyKeys need to be present in `node`
match, _ := requiredNodeAffinity.Match(node)
if !match || !nodeLabelsMatchSpreadConstraints(node.Labels, state.Constraints) {
return
}
for _, c := range state.Constraints {
pair := topologyPair{key: c.TopologyKey, value: node.Labels[c.TopologyKey]}
// If current topology pair is not associated with any candidate node,
// continue to avoid unnecessary calculation.
// Per-node counts are also skipped, as they are done during Score.
tpCount := state.TopologyPairToPodCounts[pair]
if tpCount == nil {
continue
}
count := countPodsMatchSelector(nodeInfo.Pods, c.Selector, pod.Namespace)
atomic.AddInt64(tpCount, int64(count))
}
}
pl.parallelizer.Until(ctx, len(allNodes), processAllNode)
cycleState.Write(preScoreStateKey, state)
return nil
}
// initPreScoreState iterates "filteredNodes" to filter out the nodes which
// don't have required topologyKey(s), and initialize:
// 1) s.TopologyPairToPodCounts: keyed with both eligible topology pair and node names.
// 2) s.IgnoredNodes: the set of nodes that shouldn't be scored.
// 3) s.TopologyNormalizingWeight: The weight to be given to each constraint based on the number of values in a topology.
func (pl *PodTopologySpread) initPreScoreState(s *preScoreState, pod *v1.Pod, filteredNodes []*v1.Node) error {
var err error
if len(pod.Spec.TopologySpreadConstraints) > 0 {
s.Constraints, err = filterTopologySpreadConstraints(pod.Spec.TopologySpreadConstraints, v1.ScheduleAnyway)
if err != nil {
return fmt.Errorf("obtaining pod's soft topology spread constraints: %w", err)
}
} else {
s.Constraints, err = pl.buildDefaultConstraints(pod, v1.ScheduleAnyway)
if err != nil {
return fmt.Errorf("setting default soft topology spread constraints: %w", err)
}
}
if len(s.Constraints) == 0 {
return nil
}
topoSize := make([]int, len(s.Constraints))
for _, node := range filteredNodes {
if !nodeLabelsMatchSpreadConstraints(node.Labels, s.Constraints) {
// Nodes which don't have all required topologyKeys present are ignored
// when scoring later.
s.IgnoredNodes.Insert(node.Name)
continue
}
for i, constraint := range s.Constraints {
// per-node counts are calculated during Score.
if constraint.TopologyKey == v1.LabelHostname {
continue
}
pair := topologyPair{key: constraint.TopologyKey, value: node.Labels[constraint.TopologyKey]}
if s.TopologyPairToPodCounts[pair] == nil {
s.TopologyPairToPodCounts[pair] = new(int64)
topoSize[i]++
}
}
}
s.TopologyNormalizingWeight = make([]float64, len(s.Constraints))
for i, c := range s.Constraints {
sz := topoSize[i]
if c.TopologyKey == v1.LabelHostname {
sz = len(filteredNodes) - len(s.IgnoredNodes)
}
s.TopologyNormalizingWeight[i] = topologyNormalizingWeight(sz)
}
return nil
}
func countPodsMatchSelector(podInfos []*framework.PodInfo, selector labels.Selector, ns string) int {
count := 0
for _, p := range podInfos {
// Bypass terminating Pod (see #87621).
if p.Pod.DeletionTimestamp != nil || p.Pod.Namespace != ns {
continue
}
if selector.Matches(labels.Set(p.Pod.Labels)) {
count++
}
}
return count
}
Score
podtopologyspread
- 获取node信息
- 如果node在s.IgnoredNodes里,直接返回
- 遍历s.Constraints,根据PreScore中的count和s.TopologyNormalizingWeight权重为node打分
pkg/scheduler/framework/plugins/podtopologyspread/scoring.go
// Score invoked at the Score extension point.
// The "score" returned in this function is the matching number of pods on the `nodeName`,
// it is normalized later.
func (pl *PodTopologySpread) Score(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
nodeInfo, err := pl.sharedLister.NodeInfos().Get(nodeName)
if err != nil {
return 0, framework.AsStatus(fmt.Errorf("getting node %q from Snapshot: %w", nodeName, err))
}
node := nodeInfo.Node()
s, err := getPreScoreState(cycleState)
if err != nil {
return 0, framework.AsStatus(err)
}
// Return if the node is not qualified.
if s.IgnoredNodes.Has(node.Name) {
return 0, nil
}
// For each present <pair>, current node gets a credit of <matchSum>.
// And we sum up <matchSum> and return it as this node's score.
var score float64
for i, c := range s.Constraints {
if tpVal, ok := node.Labels[c.TopologyKey]; ok {
var cnt int64
if c.TopologyKey == v1.LabelHostname {
cnt = int64(countPodsMatchSelector(nodeInfo.Pods, c.Selector, pod.Namespace))
} else {
pair := topologyPair{key: c.TopologyKey, value: tpVal}
cnt = *s.TopologyPairToPodCounts[pair]
}
score += scoreForCount(cnt, c.MaxSkew, s.TopologyNormalizingWeight[i])
}
}
return int64(score), nil
}
noderesources
- 记录resourceToWeightMap中存在的资源名称的requested和allocatable
- 调用scorer
// resourceToWeightMap contains resource name and weight.
type resourceToWeightMap map[v1.ResourceName]int64
const (
// CPU, in cores. (500m = .5 cores)
ResourceCPU ResourceName = "cpu"
// Memory, in bytes. (500Gi = 500GiB = 500 * 1024 * 1024 * 1024)
ResourceMemory ResourceName = "memory"
// Volume size, in bytes (e,g. 5Gi = 5GiB = 5 * 1024 * 1024 * 1024)
ResourceStorage ResourceName = "storage"
// Local ephemeral storage, in bytes. (500Gi = 500GiB = 500 * 1024 * 1024 * 1024)
// The resource name for ResourceEphemeralStorage is alpha and it can change across releases.
ResourceEphemeralStorage ResourceName = "ephemeral-storage"
)
pkg/scheduler/framework/plugins/noderesources/resource_allocation.go
// score will use `scorer` function to calculate the score.
func (r *resourceAllocationScorer) score(
pod *v1.Pod,
nodeInfo *framework.NodeInfo) (int64, *framework.Status) {
node := nodeInfo.Node()
if node == nil {
return 0, framework.NewStatus(framework.Error, "node not found")
}
if r.resourceToWeightMap == nil {
return 0, framework.NewStatus(framework.Error, "resources not found")
}
requested := make(resourceToValueMap, len(r.resourceToWeightMap))
allocatable := make(resourceToValueMap, len(r.resourceToWeightMap))
for resource := range r.resourceToWeightMap {
allocatable[resource], requested[resource] = calculateResourceAllocatableRequest(nodeInfo, pod, resource)
}
var score int64
// Check if the pod has volumes and this could be added to scorer function for balanced resource allocation.
if len(pod.Spec.Volumes) > 0 && utilfeature.DefaultFeatureGate.Enabled(features.BalanceAttachedNodeVolumes) && nodeInfo.TransientInfo != nil {
score = r.scorer(requested, allocatable, true, nodeInfo.TransientInfo.TransNodeInfo.RequestedVolumes, nodeInfo.TransientInfo.TransNodeInfo.AllocatableVolumesCount)
} else {
score = r.scorer(requested, allocatable, false, 0, 0)
}
if klog.V(10).Enabled() {
if len(pod.Spec.Volumes) > 0 && utilfeature.DefaultFeatureGate.Enabled(features.BalanceAttachedNodeVolumes) && nodeInfo.TransientInfo != nil {
klog.Infof(
"%v -> %v: %v, map of allocatable resources %v, map of requested resources %v , allocatable volumes %d, requested volumes %d, score %d",
pod.Name, node.Name, r.Name,
allocatable, requested, nodeInfo.TransientInfo.TransNodeInfo.AllocatableVolumesCount,
nodeInfo.TransientInfo.TransNodeInfo.RequestedVolumes,
score,
)
} else {
klog.Infof(
"%v -> %v: %v, map of allocatable resources %v, map of requested resources %v ,score %d,",
pod.Name, node.Name, r.Name,
allocatable, requested, score,
)
}
}
return score, nil
}
noderesources.BalancedAllocationName
- 获取nodeInfo
- 调用score,score中调用balancedResourceScorer
- balancedResourceScorer a. 计算cpu,mem的requested和allocable比值(如果设置了features.BalanceAttachedNodeVolumes,也计算volume比值) b. cpu比值与mem比值差的绝对值越小,分数越高(如果有volume则计算法方差,方差越小分数越高)
pkg/scheduler/framework/plugins/noderesources/balanced_allocation.go
// Score invoked at the score extension point.
func (ba *BalancedAllocation) Score(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
nodeInfo, err := ba.handle.SnapshotSharedLister().NodeInfos().Get(nodeName)
if err != nil {
return 0, framework.AsStatus(fmt.Errorf("getting node %q from Snapshot: %w", nodeName, err))
}
// ba.score favors nodes with balanced resource usage rate.
// It calculates the difference between the cpu and memory fraction of capacity,
// and prioritizes the host based on how close the two metrics are to each other.
// Detail: score = (1 - variance(cpuFraction,memoryFraction,volumeFraction)) * MaxNodeScore. The algorithm is partly inspired by:
// "Wei Huang et al. An Energy Efficient Virtual Machine Placement Algorithm with Balanced
// Resource Utilization"
return ba.score(pod, nodeInfo)
}
// todo: use resource weights in the scorer function
func balancedResourceScorer(requested, allocable resourceToValueMap, includeVolumes bool, requestedVolumes int, allocatableVolumes int) int64 {
// This to find a node which has most balanced CPU, memory and volume usage.
cpuFraction := fractionOfCapacity(requested[v1.ResourceCPU], allocable[v1.ResourceCPU])
memoryFraction := fractionOfCapacity(requested[v1.ResourceMemory], allocable[v1.ResourceMemory])
// fractions might be greater than 1 because pods with no requests get minimum
// values.
if cpuFraction > 1 {
cpuFraction = 1
}
if memoryFraction > 1 {
memoryFraction = 1
}
if includeVolumes && utilfeature.DefaultFeatureGate.Enabled(features.BalanceAttachedNodeVolumes) && allocatableVolumes > 0 {
volumeFraction := float64(requestedVolumes) / float64(allocatableVolumes)
if volumeFraction >= 1 {
// if requested >= capacity, the corresponding host should never be preferred.
return 0
}
// Compute variance for all the three fractions.
mean := (cpuFraction + memoryFraction + volumeFraction) / float64(3)
variance := float64((((cpuFraction - mean) * (cpuFraction - mean)) + ((memoryFraction - mean) * (memoryFraction - mean)) + ((volumeFraction - mean) * (volumeFraction - mean))) / float64(3))
// Since the variance is between positive fractions, it will be positive fraction. 1-variance lets the
// score to be higher for node which has least variance and multiplying it with `MaxNodeScore` provides the scaling
// factor needed.
return int64((1 - variance) * float64(framework.MaxNodeScore))
}
// Upper and lower boundary of difference between cpuFraction and memoryFraction are -1 and 1
// respectively. Multiplying the absolute value of the difference by `MaxNodeScore` scales the value to
// 0-MaxNodeScore with 0 representing well balanced allocation and `MaxNodeScore` poorly balanced. Subtracting it from
// `MaxNodeScore` leads to the score which also scales from 0 to `MaxNodeScore` while `MaxNodeScore` representing well balanced.
diff := math.Abs(cpuFraction - memoryFraction)
return int64((1 - diff) * float64(framework.MaxNodeScore))
}
noderesources.LeastAllocatedName
- 获取nodeInfo
- 调用score,score中调用leastResourceScorer
- leastResourceScorer a. 遍历resourceToWeightMap中的资源类型和权重 b. 根据1-资源申请率的正比计算分数,资源申请率越低分数越高
// Score invoked at the score extension point.
func (la *LeastAllocated) Score(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
nodeInfo, err := la.handle.SnapshotSharedLister().NodeInfos().Get(nodeName)
if err != nil {
return 0, framework.AsStatus(fmt.Errorf("getting node %q from Snapshot: %w", nodeName, err))
}
// la.score favors nodes with fewer requested resources.
// It calculates the percentage of memory and CPU requested by pods scheduled on the node, and
// prioritizes based on the minimum of the average of the fraction of requested to capacity.
//
// Details:
// (cpu((capacity-sum(requested))*MaxNodeScore/capacity) + memory((capacity-sum(requested))*MaxNodeScore/capacity))/weightSum
return la.score(pod, nodeInfo)
}
func leastResourceScorer(resToWeightMap resourceToWeightMap) func(resourceToValueMap, resourceToValueMap, bool, int, int) int64 {
return func(requested, allocable resourceToValueMap, includeVolumes bool, requestedVolumes int, allocatableVolumes int) int64 {
var nodeScore, weightSum int64
for resource, weight := range resToWeightMap {
resourceScore := leastRequestedScore(requested[resource], allocable[resource])
nodeScore += resourceScore * weight
weightSum += weight
}
return nodeScore / weightSum
}
}
// The unused capacity is calculated on a scale of 0-MaxNodeScore
// 0 being the lowest priority and `MaxNodeScore` being the highest.
// The more unused resources the higher the score is.
func leastRequestedScore(requested, capacity int64) int64 {
if capacity == 0 {
return 0
}
if requested > capacity {
return 0
}
return ((capacity - requested) * int64(framework.MaxNodeScore)) / capacity
}
noderesources.MostAllocatedName
- 获取nodeInfo
- 调用score,score中调用mostResourceScorer
- mostResourceScorer a. 遍历resourceToWeightMap中的资源类型和权重 b. 根据资源申请率的正比计算分数,资源申请率越高分数越高
// Score invoked at the Score extension point.
func (ma *MostAllocated) Score(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
nodeInfo, err := ma.handle.SnapshotSharedLister().NodeInfos().Get(nodeName)
if err != nil {
return 0, framework.AsStatus(fmt.Errorf("getting node %q from Snapshot: %w", nodeName, err))
}
// ma.score favors nodes with most requested resources.
// It calculates the percentage of memory and CPU requested by pods scheduled on the node, and prioritizes
// based on the maximum of the average of the fraction of requested to capacity.
// Details: (cpu(MaxNodeScore * sum(requested) / capacity) + memory(MaxNodeScore * sum(requested) / capacity)) / weightSum
return ma.score(pod, nodeInfo)
}
func mostResourceScorer(resToWeightMap resourceToWeightMap) func(requested, allocable resourceToValueMap, includeVolumes bool, requestedVolumes int, allocatableVolumes int) int64 {
return func(requested, allocable resourceToValueMap, includeVolumes bool, requestedVolumes int, allocatableVolumes int) int64 {
var nodeScore, weightSum int64
for resource, weight := range resToWeightMap {
resourceScore := mostRequestedScore(requested[resource], allocable[resource])
nodeScore += resourceScore * weight
weightSum += weight
}
return (nodeScore / weightSum)
}
}
// The used capacity is calculated on a scale of 0-MaxNodeScore (MaxNodeScore is
// constant with value set to 100).
// 0 being the lowest priority and 100 being the highest.
// The more resources are used the higher the score is. This function
// is almost a reversed version of noderesources.leastRequestedScore.
func mostRequestedScore(requested, capacity int64) int64 {
if capacity == 0 {
return 0
}
if requested > capacity {
// `requested` might be greater than `capacity` because pods with no
// requests get minimum values.
requested = capacity
}
return (requested * framework.MaxNodeScore) / capacity
}