本文基于kubernetes v1.26.0
概述
kube-scheduller是k8s的核心组件之一,负责为pod选择最优node kube-scheduller的预选是为了筛选出所有满足pod要求的node,然后把结果传给后续流程
架构分析
A picture is worth a thousand words(从别人的博客里偷来的图)
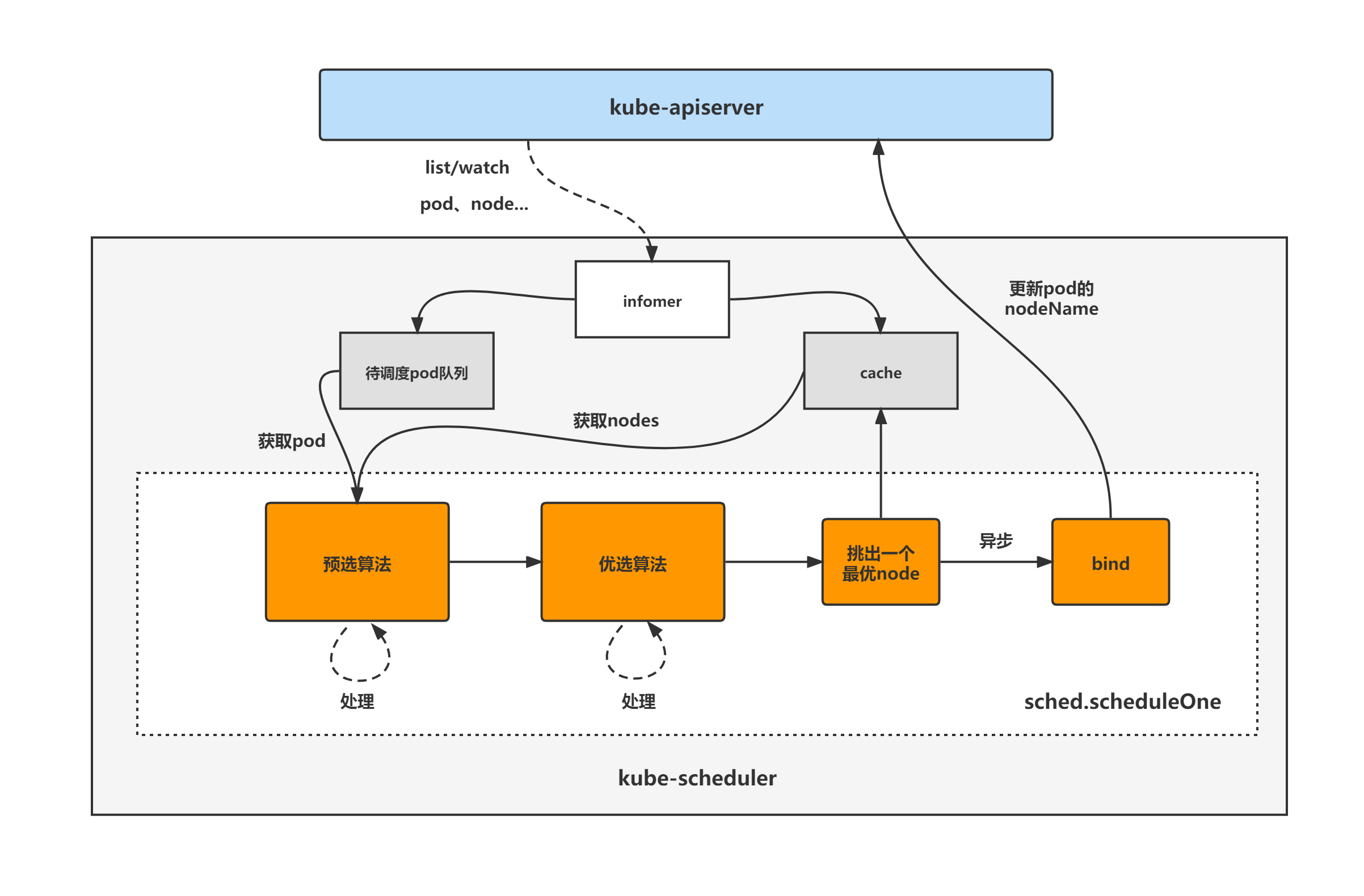
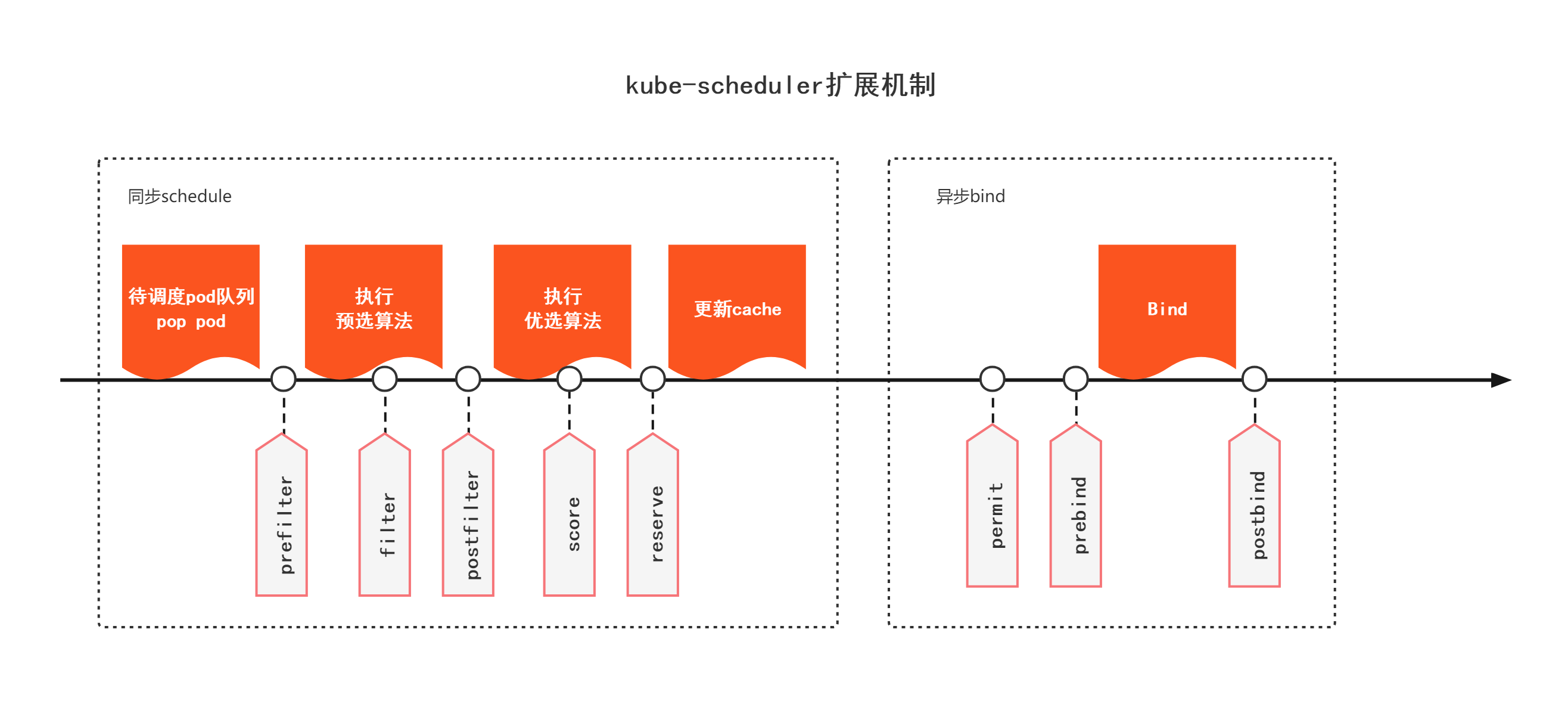
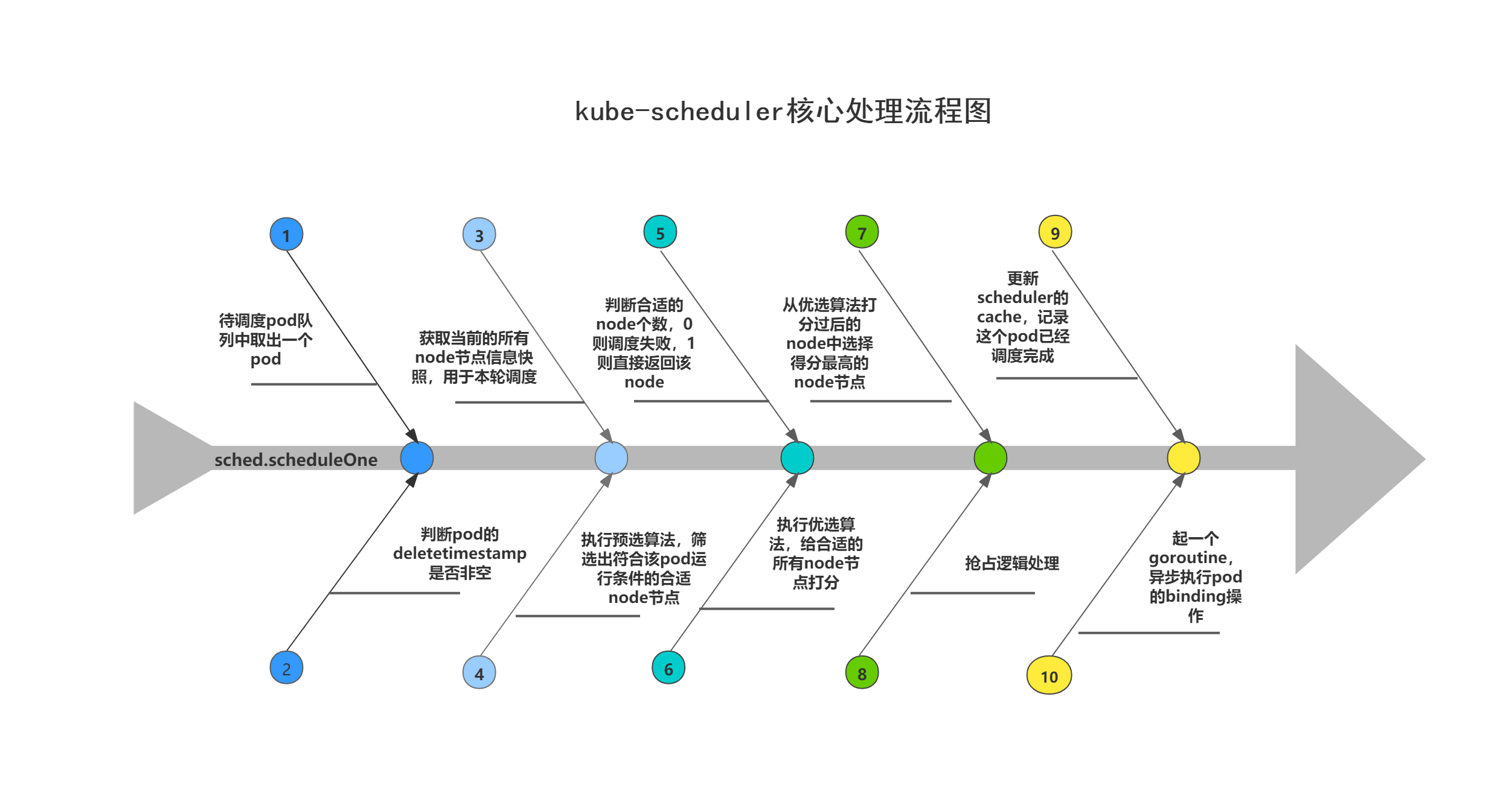
流程分析
调用栈
main() cmd/kube-scheduler/scheduler.go | NewSchedulerCommand() cmd/kube-scheduler/app/server.go | runCommand(*cobra.Command,*options.Options,…Option) cmd/kube-scheduler/app/server.go | Run(context.Context,*schedulerserverconfig.CompletedConfig,*scheduler.Scheduler) cmd/kube-scheduler/app/server.go | LeaderElector cmd/kube-scheduler/app/server.go | (sched *Scheduler) Run(context.Context) pkg/scheduler/scheduler.go | (sched *Scheduler) scheduleOne(context.Context) pkg/scheduler/scheduler.go | (sched *Scheduler) schedulePod(context.Context,framework.Framework,*framework.CycleState,*v1.Pod) pkg/scheduler/schedule_one.go | (sched *Scheduler) findNodesThatFitPod(context.Context,*framework.Framework,*framework.CycleState, pod *v1.Pod) pkg/scheduler/schedule_one.go
预选过程
1.通过pod信息调用PreFilter插件,初步筛选出节点 2.判断每一个通过初步筛选的node适不适合运行pod 3.对filter出来的node列表进一步按顺序通过Extender筛选 pkg/scheduler/schedule_one.go
// Filters the nodes to find the ones that fit the pod based on the framework
// filter plugins and filter extenders.
func (sched *Scheduler) findNodesThatFitPod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) ([]*v1.Node, framework.Diagnosis, error) {
diagnosis := framework.Diagnosis{
NodeToStatusMap: make(framework.NodeToStatusMap),
UnschedulablePlugins: sets.NewString(),
}
// List所有Node的信息
allNodes, err := sched.nodeInfoSnapshot.NodeInfos().List()
if err != nil {
return nil, diagnosis, err
}
// Run "prefilter" plugins.
// 通过pod信息调用PreFilter插件,初步筛选出节点
preRes, s := fwk.RunPreFilterPlugins(ctx, state, pod)
if !s.IsSuccess() {
if !s.IsUnschedulable() {
return nil, diagnosis, s.AsError()
}
// Record the messages from PreFilter in Diagnosis.PreFilterMsg.
diagnosis.PreFilterMsg = s.Message()
klog.V(5).InfoS("Status after running PreFilter plugins for pod", "pod", klog.KObj(pod), "status", s)
// Status satisfying IsUnschedulable() gets injected into diagnosis.UnschedulablePlugins.
if s.FailedPlugin() != "" {
diagnosis.UnschedulablePlugins.Insert(s.FailedPlugin())
}
return nil, diagnosis, nil
}
// "NominatedNodeName" can potentially be set in a previous scheduling cycle as a result of preemption.
// This node is likely the only candidate that will fit the pod, and hence we try it first before iterating over all nodes.
if len(pod.Status.NominatedNodeName) > 0 {
feasibleNodes, err := sched.evaluateNominatedNode(ctx, pod, fwk, state, diagnosis)
if err != nil {
klog.ErrorS(err, "Evaluation failed on nominated node", "pod", klog.KObj(pod), "node", pod.Status.NominatedNodeName)
}
// Nominated node passes all the filters, scheduler is good to assign this node to the pod.
if len(feasibleNodes) != 0 {
return feasibleNodes, diagnosis, nil
}
}
nodes := allNodes
if !preRes.AllNodes() {
nodes = make([]*framework.NodeInfo, 0, len(preRes.NodeNames))
for n := range preRes.NodeNames {
nInfo, err := sched.nodeInfoSnapshot.NodeInfos().Get(n)
if err != nil {
return nil, diagnosis, err
}
nodes = append(nodes, nInfo)
}
}
// 判断每一个通过初步筛选的node适不适合运行pod
feasibleNodes, err := sched.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, nodes)
// always try to update the sched.nextStartNodeIndex regardless of whether an error has occurred
// this is helpful to make sure that all the nodes have a chance to be searched
processedNodes := len(feasibleNodes) + len(diagnosis.NodeToStatusMap)
sched.nextStartNodeIndex = (sched.nextStartNodeIndex + processedNodes) % len(nodes)
if err != nil {
return nil, diagnosis, err
}
// 对filter出来的node列表进一步按顺序通过Extender筛选
feasibleNodes, err = findNodesThatPassExtenders(sched.Extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)
if err != nil {
return nil, diagnosis, err
}
return feasibleNodes, diagnosis, nil
}
1.按顺序运行Prefilter插件 2.每个Prefilter插件的结果取交集
// RunPreFilterPlugins runs the set of configured PreFilter plugins. It returns
// *Status and its code is set to non-success if any of the plugins returns
// anything but Success. If a non-success status is returned, then the scheduling
// cycle is aborted.
func (f *frameworkImpl) RunPreFilterPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod) (_ *framework.PreFilterResult, status *framework.Status) {
startTime := time.Now()
defer func() {
metrics.FrameworkExtensionPointDuration.WithLabelValues(preFilter, status.Code().String(), f.profileName).Observe(metrics.SinceInSeconds(startTime))
}()
var result *framework.PreFilterResult
var pluginsWithNodes []string
// 按顺序运行Prefilter插件
for _, pl := range f.preFilterPlugins {
r, s := f.runPreFilterPlugin(ctx, pl, state, pod)
if !s.IsSuccess() {
s.SetFailedPlugin(pl.Name())
if s.IsUnschedulable() {
return nil, s
}
return nil, framework.AsStatus(fmt.Errorf("running PreFilter plugin %q: %w", pl.Name(), s.AsError())).WithFailedPlugin(pl.Name())
}
if !r.AllNodes() {
pluginsWithNodes = append(pluginsWithNodes, pl.Name())
}
// 结果取交集
result = result.Merge(r)
// 所有节点都不合适
if !result.AllNodes() && len(result.NodeNames) == 0 {
msg := fmt.Sprintf("node(s) didn't satisfy plugin(s) %v simultaneously", pluginsWithNodes)
if len(pluginsWithNodes) == 1 {
msg = fmt.Sprintf("node(s) didn't satisfy plugin %v", pluginsWithNodes[0])
}
return nil, framework.NewStatus(framework.Unschedulable, msg)
}
}
return result, nil
}
// findNodesThatPassFilters finds the nodes that fit the filter plugins.
func (sched *Scheduler) findNodesThatPassFilters(
ctx context.Context,
fwk framework.Framework,
state *framework.CycleState,
pod *v1.Pod,
diagnosis framework.Diagnosis,
nodes []*framework.NodeInfo) ([]*v1.Node, error) {
numAllNodes := len(nodes)
numNodesToFind := sched.numFeasibleNodesToFind(fwk.PercentageOfNodesToScore(), int32(numAllNodes))
// Create feasible list with enough space to avoid growing it
// and allow assigning.
feasibleNodes := make([]*v1.Node, numNodesToFind)
if !fwk.HasFilterPlugins() {
for i := range feasibleNodes {
feasibleNodes[i] = nodes[(sched.nextStartNodeIndex+i)%numAllNodes].Node()
}
return feasibleNodes, nil
}
errCh := parallelize.NewErrorChannel()
var statusesLock sync.Mutex
var feasibleNodesLen int32
ctx, cancel := context.WithCancel(ctx)
defer cancel()
checkNode := func(i int) {
// We check the nodes starting from where we left off in the previous scheduling cycle,
// this is to make sure all nodes have the same chance of being examined across pods.
nodeInfo := nodes[(sched.nextStartNodeIndex+i)%numAllNodes]
status := fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)
if status.Code() == framework.Error {
errCh.SendErrorWithCancel(status.AsError(), cancel)
return
}
if status.IsSuccess() {
length := atomic.AddInt32(&feasibleNodesLen, 1)
if length > numNodesToFind {
cancel()
atomic.AddInt32(&feasibleNodesLen, -1)
} else {
feasibleNodes[length-1] = nodeInfo.Node()
}
} else {
statusesLock.Lock()
diagnosis.NodeToStatusMap[nodeInfo.Node().Name] = status
diagnosis.UnschedulablePlugins.Insert(status.FailedPlugin())
statusesLock.Unlock()
}
}
beginCheckNode := time.Now()
statusCode := framework.Success
defer func() {
// We record Filter extension point latency here instead of in framework.go because framework.RunFilterPlugins
// function is called for each node, whereas we want to have an overall latency for all nodes per scheduling cycle.
// Note that this latency also includes latency for `addNominatedPods`, which calls framework.RunPreFilterAddPod.
metrics.FrameworkExtensionPointDuration.WithLabelValues(frameworkruntime.Filter, statusCode.String(), fwk.ProfileName()).Observe(metrics.SinceInSeconds(beginCheckNode))
}()
// Stops searching for more nodes once the configured number of feasible nodes
// are found.
// 运行node数个goroutine运行过滤插件
fwk.Parallelizer().Until(ctx, numAllNodes, checkNode, frameworkruntime.Filter)
feasibleNodes = feasibleNodes[:feasibleNodesLen]
if err := errCh.ReceiveError(); err != nil {
statusCode = framework.Error
return feasibleNodes, err
}
return feasibleNodes, nil
}
按顺序运行filter插件
// RunFilterPlugins runs the set of configured Filter plugins for pod on
// the given node. If any of these plugins doesn't return "Success", the
// given node is not suitable for running pod.
// Meanwhile, the failure message and status are set for the given node.
func (f *frameworkImpl) RunFilterPlugins(
ctx context.Context,
state *framework.CycleState,
pod *v1.Pod,
nodeInfo *framework.NodeInfo,
) framework.PluginToStatus {
statuses := make(framework.PluginToStatus)
for _, pl := range f.filterPlugins {
pluginStatus := f.runFilterPlugin(ctx, pl, state, pod, nodeInfo)
if !pluginStatus.IsSuccess() {
if !pluginStatus.IsUnschedulable() {
// Filter plugins are not supposed to return any status other than
// Success or Unschedulable.
errStatus := framework.AsStatus(fmt.Errorf("running %q filter plugin: %w", pl.Name(), pluginStatus.AsError())).WithFailedPlugin(pl.Name())
return map[string]*framework.Status{pl.Name(): errStatus}
}
pluginStatus.SetFailedPlugin(pl.Name())
statuses[pl.Name()] = pluginStatus
}
}
return statuses
}
按顺序执行ExtenderFilter,每次ExtenderFilter处理上次ExtenderFilter筛选的结果,通过ExtenderFilter的node数层层递减
func findNodesThatPassExtenders(extenders []framework.Extender, pod *v1.Pod, feasibleNodes []*v1.Node, statuses framework.NodeToStatusMap) ([]*v1.Node, error) {
// Extenders are called sequentially.
// Nodes in original feasibleNodes can be excluded in one extender, and pass on to the next
// extender in a decreasing manner.
for _, extender := range extenders {
if len(feasibleNodes) == 0 {
break
}
if !extender.IsInterested(pod) {
continue
}
// Status of failed nodes in failedAndUnresolvableMap will be added or overwritten in <statuses>,
// so that the scheduler framework can respect the UnschedulableAndUnresolvable status for
// particular nodes, and this may eventually improve preemption efficiency.
// Note: users are recommended to configure the extenders that may return UnschedulableAndUnresolvable
// status ahead of others.
feasibleList, failedMap, failedAndUnresolvableMap, err := extender.Filter(pod, feasibleNodes)
if err != nil {
if extender.IsIgnorable() {
klog.InfoS("Skipping extender as it returned error and has ignorable flag set", "extender", extender, "err", err)
continue
}
return nil, err
}
for failedNodeName, failedMsg := range failedAndUnresolvableMap {
var aggregatedReasons []string
if _, found := statuses[failedNodeName]; found {
aggregatedReasons = statuses[failedNodeName].Reasons()
}
aggregatedReasons = append(aggregatedReasons, failedMsg)
statuses[failedNodeName] = framework.NewStatus(framework.UnschedulableAndUnresolvable, aggregatedReasons...)
}
for failedNodeName, failedMsg := range failedMap {
if _, found := failedAndUnresolvableMap[failedNodeName]; found {
// failedAndUnresolvableMap takes precedence over failedMap
// note that this only happens if the extender returns the node in both maps
continue
}
if _, found := statuses[failedNodeName]; !found {
statuses[failedNodeName] = framework.NewStatus(framework.Unschedulable, failedMsg)
} else {
statuses[failedNodeName].AppendReason(failedMsg)
}
}
feasibleNodes = feasibleList
}
return feasibleNodes, nil
}
默认启用的插件
PreFilter: config.PluginSet{
Enabled: []config.Plugin{
{Name: names.NodeAffinity},
{Name: names.NodePorts},
{Name: names.NodeResourcesFit},
{Name: names.VolumeRestrictions},
{Name: names.VolumeBinding},
{Name: names.PodTopologySpread},
{Name: names.InterPodAffinity},
},
},
Filter: config.PluginSet{
Enabled: []config.Plugin{
{Name: names.NodeUnschedulable},
{Name: names.NodeName},
{Name: names.TaintToleration},
{Name: names.NodeAffinity},
{Name: names.NodePorts},
{Name: names.NodeResourcesFit},
{Name: names.VolumeRestrictions},
...
{Name: names.NodeVolumeLimits},
...
{Name: names.VolumeBinding},
{Name: names.VolumeZone},
{Name: names.PodTopologySpread},
{Name: names.InterPodAffinity},
},
},
prefilter
NodeAffinity
节点亲和性初筛 1.记录Pod的NodeSelector和NodeAffinity信息 2.有MatchFields & metav1.ObjectNameField & NodeSelectorOpIn的情况下,筛选出指定的节点,否则返回AllNode pkg/scheduler/framework/plugins/nodeaffinity/node_affinity.go
// PreFilter builds and writes cycle state used by Filter.
func (pl *NodeAffinity) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
// 记录NodeSelector和NodeAffinity信息
state := &preFilterState{requiredNodeSelectorAndAffinity: nodeaffinity.GetRequiredNodeAffinity(pod)}
cycleState.Write(preFilterStateKey, state)
affinity := pod.Spec.Affinity
if affinity == nil ||
affinity.NodeAffinity == nil ||
affinity.NodeAffinity.RequiredDuringSchedulingIgnoredDuringExecution == nil ||
len(affinity.NodeAffinity.RequiredDuringSchedulingIgnoredDuringExecution.NodeSelectorTerms) == 0 {
return nil, nil
}
// Check if there is affinity to a specific node and return it.
// 只有MatchFields & metav1.ObjectNameField & NodeSelectorOpIn这种情况下,才会筛选出指定的节点
terms := affinity.NodeAffinity.RequiredDuringSchedulingIgnoredDuringExecution.NodeSelectorTerms
var nodeNames sets.String
for _, t := range terms {
var termNodeNames sets.String
for _, r := range t.MatchFields {
if r.Key == metav1.ObjectNameField && r.Operator == v1.NodeSelectorOpIn {
// The requirements represent ANDed constraints, and so we need to
// find the intersection of nodes.
s := sets.NewString(r.Values...)
if termNodeNames == nil {
termNodeNames = s
} else {
termNodeNames = termNodeNames.Intersection(s)
}
}
}
if termNodeNames == nil {
// If this term has no node.Name field affinity,
// then all nodes are eligible because the terms are ORed.
return nil, nil
}
// If the set is empty, it means the terms had affinity to different
// sets of nodes, and since they are ANDed, then the pod will not match any node.
if len(termNodeNames) == 0 {
return nil, framework.NewStatus(framework.UnschedulableAndUnresolvable, errReasonConflict)
}
nodeNames = nodeNames.Union(termNodeNames)
}
if nodeNames != nil {
return &framework.PreFilterResult{NodeNames: nodeNames}, nil
}
return nil, nil
}
NodePorts
NodePorts初筛,记录所有容器的所有端口信息,返回AllNode pkg/scheduler/framework/plugins/nodeports/node_ports.go
// PreFilter invoked at the prefilter extension point.
func (pl *NodePorts) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
s := getContainerPorts(pod)
cycleState.Write(preFilterStateKey, preFilterState(s))
return nil, nil
}
// getContainerPorts returns the used host ports of Pods: if 'port' was used, a 'port:true' pair
// will be in the result; but it does not resolve port conflict.
func getContainerPorts(pods ...*v1.Pod) []*v1.ContainerPort {
ports := []*v1.ContainerPort{}
for _, pod := range pods {
for j := range pod.Spec.Containers {
container := &pod.Spec.Containers[j]
for k := range container.Ports {
ports = append(ports, &container.Ports[k])
}
}
}
return ports
}
NodeResourcesFit
节点资源初筛,计算并记录节点所需资源,返回AllNode pkg/scheduler/framework/plugins/noderesources/fit.go
// PreFilter invoked at the prefilter extension point.
func (f *Fit) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
cycleState.Write(preFilterStateKey, computePodResourceRequest(pod))
return nil, nil
}
// computePodResourceRequest returns a framework.Resource that covers the largest
// width in each resource dimension. Because init-containers run sequentially, we collect
// the max in each dimension iteratively. In contrast, we sum the resource vectors for
// regular containers since they run simultaneously.
//
// # The resources defined for Overhead should be added to the calculated Resource request sum
//
// Example:
//
// Pod:
//
// InitContainers
// IC1:
// CPU: 2
// Memory: 1G
// IC2:
// CPU: 2
// Memory: 3G
// Containers
// C1:
// CPU: 2
// Memory: 1G
// C2:
// CPU: 1
// Memory: 1G
//
// Result: CPU: 3, Memory: 3G
func computePodResourceRequest(pod *v1.Pod) *preFilterState {
result := &preFilterState{}
for _, container := range pod.Spec.Containers {
result.Add(container.Resources.Requests)
}
// take max_resource(sum_pod, any_init_container)
for _, container := range pod.Spec.InitContainers {
result.SetMaxResource(container.Resources.Requests)
}
// If Overhead is being utilized, add to the total requests for the pod
if pod.Spec.Overhead != nil {
result.Add(pod.Spec.Overhead)
}
return result
}
VolumeRestrictions
VolumeRestrictions初筛,检查PVC pkg/scheduler/framework/plugins/volumerestrictions/volume_restrictions.go
func (pl *VolumeRestrictions) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
if pl.enableReadWriteOncePod {
return nil, pl.isReadWriteOncePodAccessModeConflict(ctx, pod)
}
return nil, framework.NewStatus(framework.Success)
}
// isReadWriteOncePodAccessModeConflict checks if a pod uses a PVC with the ReadWriteOncePod access mode.
// This access mode restricts volume access to a single pod on a single node. Since only a single pod can
// use a ReadWriteOncePod PVC, mark any other pods attempting to use this PVC as UnschedulableAndUnresolvable.
// TODO(#103132): Mark pod as Unschedulable and add preemption logic.
func (pl *VolumeRestrictions) isReadWriteOncePodAccessModeConflict(ctx context.Context, pod *v1.Pod) *framework.Status {
for _, volume := range pod.Spec.Volumes {
if volume.PersistentVolumeClaim == nil {
continue
}
pvc, err := pl.pvcLister.PersistentVolumeClaims(pod.Namespace).Get(volume.PersistentVolumeClaim.ClaimName)
if err != nil {
if apierrors.IsNotFound(err) {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, err.Error())
}
return framework.AsStatus(err)
}
if !v1helper.ContainsAccessMode(pvc.Spec.AccessModes, v1.ReadWriteOncePod) {
continue
}
key := framework.GetNamespacedName(pod.Namespace, volume.PersistentVolumeClaim.ClaimName)
if pl.sharedLister.StorageInfos().IsPVCUsedByPods(key) {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReasonReadWriteOncePodConflict)
}
}
return nil
}
VolumeBinding
volume_binding初筛,检查pod的pvc有没有被绑定 pkg/scheduler/framework/plugins/volumebinding/volume_binding.go
// PreFilter invoked at the prefilter extension point to check if pod has all
// immediate PVCs bound. If not all immediate PVCs are bound, an
// UnschedulableAndUnresolvable is returned.
func (pl *VolumeBinding) PreFilter(ctx context.Context, state *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
// If pod does not reference any PVC, we don't need to do anything.
if hasPVC, err := pl.podHasPVCs(pod); err != nil {
return nil, framework.NewStatus(framework.UnschedulableAndUnresolvable, err.Error())
} else if !hasPVC {
state.Write(stateKey, &stateData{skip: true})
return nil, nil
}
boundClaims, claimsToBind, unboundClaimsImmediate, err := pl.Binder.GetPodVolumes(pod)
if err != nil {
return nil, framework.AsStatus(err)
}
if len(unboundClaimsImmediate) > 0 {
// Return UnschedulableAndUnresolvable error if immediate claims are
// not bound. Pod will be moved to active/backoff queues once these
// claims are bound by PV controller.
status := framework.NewStatus(framework.UnschedulableAndUnresolvable)
status.AppendReason("pod has unbound immediate PersistentVolumeClaims")
return nil, status
}
state.Write(stateKey, &stateData{boundClaims: boundClaims, claimsToBind: claimsToBind, podVolumesByNode: make(map[string]*PodVolumes)})
return nil, nil
}
PodTopologySpread
pod拓扑分布初筛 pkg/scheduler/framework/plugins/podtopologyspread/filtering.go
// PreFilter invoked at the prefilter extension point.
func (pl *PodTopologySpread) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
s, err := pl.calPreFilterState(ctx, pod)
if err != nil {
return nil, framework.AsStatus(err)
}
cycleState.Write(preFilterStateKey, s)
return nil, nil
}
// calPreFilterState computes preFilterState describing how pods are spread on topologies.
func (pl *PodTopologySpread) calPreFilterState(ctx context.Context, pod *v1.Pod) (*preFilterState, error) {
// 列出所有节点
allNodes, err := pl.sharedLister.NodeInfos().List()
if err != nil {
return nil, fmt.Errorf("listing NodeInfos: %w", err)
}
var constraints []topologySpreadConstraint
// 检查POD的TopologySpreadConstraints字段
if len(pod.Spec.TopologySpreadConstraints) > 0 {
// We have feature gating in APIServer to strip the spec
// so don't need to re-check feature gate, just check length of Constraints.
// 筛选出DoNotSchedule的约束
constraints, err = pl.filterTopologySpreadConstraints(
pod.Spec.TopologySpreadConstraints,
pod.Labels,
v1.DoNotSchedule,
)
if err != nil {
return nil, fmt.Errorf("obtaining pod's hard topology spread constraints: %w", err)
}
} else {
// 设置默认约束
constraints, err = pl.buildDefaultConstraints(pod, v1.DoNotSchedule)
if err != nil {
return nil, fmt.Errorf("setting default hard topology spread constraints: %w", err)
}
}
if len(constraints) == 0 {
return &preFilterState{}, nil
}
s := preFilterState{
Constraints: constraints,
TpKeyToCriticalPaths: make(map[string]*criticalPaths, len(constraints)),
TpPairToMatchNum: make(map[topologyPair]int, sizeHeuristic(len(allNodes), constraints)),
}
tpCountsByNode := make([]map[topologyPair]int, len(allNodes))
// 获取节点亲和性信息
requiredNodeAffinity := nodeaffinity.GetRequiredNodeAffinity(pod)
processNode := func(i int) {
nodeInfo := allNodes[i]
node := nodeInfo.Node()
if node == nil {
klog.ErrorS(nil, "Node not found")
return
}
// 默认为false的特性门控
if !pl.enableNodeInclusionPolicyInPodTopologySpread {
// spreading is applied to nodes that pass those filters.
// Ignore parsing errors for backwards compatibility.
if match, _ := requiredNodeAffinity.Match(node); !match {
return
}
}
// Ensure current node's labels contains all topologyKeys in 'Constraints'.
if !nodeLabelsMatchSpreadConstraints(node.Labels, constraints) {
return
}
tpCounts := make(map[topologyPair]int, len(constraints))
for _, c := range constraints {
if pl.enableNodeInclusionPolicyInPodTopologySpread &&
!c.matchNodeInclusionPolicies(pod, node, requiredNodeAffinity) {
continue
}
pair := topologyPair{key: c.TopologyKey, value: node.Labels[c.TopologyKey]}
count := countPodsMatchSelector(nodeInfo.Pods, c.Selector, pod.Namespace)
tpCounts[pair] = count
}
tpCountsByNode[i] = tpCounts
}
pl.parallelizer.Until(ctx, len(allNodes), processNode, pl.Name())
for _, tpCounts := range tpCountsByNode {
for tp, count := range tpCounts {
s.TpPairToMatchNum[tp] += count
}
}
if pl.enableMinDomainsInPodTopologySpread {
s.TpKeyToDomainsNum = make(map[string]int, len(constraints))
for tp := range s.TpPairToMatchNum {
s.TpKeyToDomainsNum[tp.key]++
}
}
// calculate min match for each topology pair
for i := 0; i < len(constraints); i++ {
key := constraints[i].TopologyKey
s.TpKeyToCriticalPaths[key] = newCriticalPaths()
}
for pair, num := range s.TpPairToMatchNum {
s.TpKeyToCriticalPaths[pair.key].update(pair.value, num)
}
return &s, nil
}
InterPodAffinity
pod间亲和性初筛 pkg/scheduler/framework/plugins/interpodaffinity/filtering.go
// PreFilter invoked at the prefilter extension point.
func (pl *InterPodAffinity) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
var allNodes []*framework.NodeInfo
var nodesWithRequiredAntiAffinityPods []*framework.NodeInfo
var err error
if allNodes, err = pl.sharedLister.NodeInfos().List(); err != nil {
return nil, framework.AsStatus(fmt.Errorf("failed to list NodeInfos: %w", err))
}
if nodesWithRequiredAntiAffinityPods, err = pl.sharedLister.NodeInfos().HavePodsWithRequiredAntiAffinityList(); err != nil {
return nil, framework.AsStatus(fmt.Errorf("failed to list NodeInfos with pods with affinity: %w", err))
}
s := &preFilterState{}
if s.podInfo, err = framework.NewPodInfo(pod); err != nil {
return nil, framework.NewStatus(framework.UnschedulableAndUnresolvable, fmt.Sprintf("parsing pod: %+v", err))
}
for i := range s.podInfo.RequiredAffinityTerms {
if err := pl.mergeAffinityTermNamespacesIfNotEmpty(&s.podInfo.RequiredAffinityTerms[i]); err != nil {
return nil, framework.AsStatus(err)
}
}
for i := range s.podInfo.RequiredAntiAffinityTerms {
if err := pl.mergeAffinityTermNamespacesIfNotEmpty(&s.podInfo.RequiredAntiAffinityTerms[i]); err != nil {
return nil, framework.AsStatus(err)
}
}
s.namespaceLabels = GetNamespaceLabelsSnapshot(pod.Namespace, pl.nsLister)
s.existingAntiAffinityCounts = pl.getExistingAntiAffinityCounts(ctx, pod, s.namespaceLabels, nodesWithRequiredAntiAffinityPods)
s.affinityCounts, s.antiAffinityCounts = pl.getIncomingAffinityAntiAffinityCounts(ctx, s.podInfo, allNodes)
cycleState.Write(preFilterStateKey, s)
return nil, nil
}
filter
NodeUnschedulable
NodeUnschedulable过滤检查节点是否不可调度和pod是否容忍不可调度污点 pkg/scheduler/framework/plugins/nodeunschedulable/node_unschedulable.go
// Filter invoked at the filter extension point.
func (pl *NodeUnschedulable) Filter(ctx context.Context, _ *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
node := nodeInfo.Node()
if node == nil {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReasonUnknownCondition)
}
// If pod tolerate unschedulable taint, it's also tolerate `node.Spec.Unschedulable`.
podToleratesUnschedulable := v1helper.TolerationsTolerateTaint(pod.Spec.Tolerations, &v1.Taint{
Key: v1.TaintNodeUnschedulable,
Effect: v1.TaintEffectNoSchedule,
})
if node.Spec.Unschedulable && !podToleratesUnschedulable {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReasonUnschedulable)
}
return nil
}
NodeName
NodeName过滤,检查pod的NodeName字段 pkg/scheduler/framework/plugins/nodename/node_name.go
// Filter invoked at the filter extension point.
func (pl *NodeName) Filter(ctx context.Context, _ *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
if nodeInfo.Node() == nil {
return framework.NewStatus(framework.Error, "node not found")
}
if !Fits(pod, nodeInfo) {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReason)
}
return nil
}
// Fits actually checks if the pod fits the node.
func Fits(pod *v1.Pod, nodeInfo *framework.NodeInfo) bool {
return len(pod.Spec.NodeName) == 0 || pod.Spec.NodeName == nodeInfo.Node().Name
}
TaintToleration
TaintToleration过滤,检查pod是否容忍节点上的所有不可调度污点 pkg/scheduler/framework/plugins/tainttoleration/taint_toleration.go
// Filter invoked at the filter extension point.
func (pl *TaintToleration) Filter(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
node := nodeInfo.Node()
if node == nil {
return framework.AsStatus(fmt.Errorf("invalid nodeInfo"))
}
taint, isUntolerated := v1helper.FindMatchingUntoleratedTaint(node.Spec.Taints, pod.Spec.Tolerations, helper.DoNotScheduleTaintsFilterFunc())
if !isUntolerated {
return nil
}
errReason := fmt.Sprintf("node(s) had untolerated taint {%s: %s}", taint.Key, taint.Value)
return framework.NewStatus(framework.UnschedulableAndUnresolvable, errReason)
}
NodeAffinity
根据Prefilter记录的Pod的NodeSelector和NodeAffinity信息过滤节点 pkg/scheduler/framework/plugins/nodeaffinity/node_affinity.go
// Filter checks if the Node matches the Pod .spec.affinity.nodeAffinity and
// the plugin's added affinity.
func (pl *NodeAffinity) Filter(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
node := nodeInfo.Node()
if node == nil {
return framework.NewStatus(framework.Error, "node not found")
}
if pl.addedNodeSelector != nil && !pl.addedNodeSelector.Match(node) {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, errReasonEnforced)
}
s, err := getPreFilterState(state)
if err != nil {
// Fallback to calculate requiredNodeSelector and requiredNodeAffinity
// here when PreFilter is disabled.
s = &preFilterState{requiredNodeSelectorAndAffinity: nodeaffinity.GetRequiredNodeAffinity(pod)}
}
// Ignore parsing errors for backwards compatibility.
match, _ := s.requiredNodeSelectorAndAffinity.Match(node)
if !match {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReasonPod)
}
return nil
}
NodePorts
检查pod的端口在节点上是否被占用 pkg/scheduler/framework/plugins/nodeports/node_ports.go
// Filter invoked at the filter extension point.
func (pl *NodePorts) Filter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
wantPorts, err := getPreFilterState(cycleState)
if err != nil {
return framework.AsStatus(err)
}
fits := fitsPorts(wantPorts, nodeInfo)
if !fits {
return framework.NewStatus(framework.Unschedulable, ErrReason)
}
return nil
}
NodeResourcesFit
检查节点上的pod数目,cpu,内存,储存等资源是否充足 pkg/scheduler/framework/plugins/noderesources/fit.go
// Filter invoked at the filter extension point.
// Checks if a node has sufficient resources, such as cpu, memory, gpu, opaque int resources etc to run a pod.
// It returns a list of insufficient resources, if empty, then the node has all the resources requested by the pod.
func (f *Fit) Filter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
s, err := getPreFilterState(cycleState)
if err != nil {
return framework.AsStatus(err)
}
insufficientResources := fitsRequest(s, nodeInfo, f.ignoredResources, f.ignoredResourceGroups)
if len(insufficientResources) != 0 {
// We will keep all failure reasons.
failureReasons := make([]string, 0, len(insufficientResources))
for i := range insufficientResources {
failureReasons = append(failureReasons, insufficientResources[i].Reason)
}
return framework.NewStatus(framework.Unschedulable, failureReasons...)
}
return nil
}
func fitsRequest(podRequest *preFilterState, nodeInfo *framework.NodeInfo, ignoredExtendedResources, ignoredResourceGroups sets.String) []InsufficientResource {
insufficientResources := make([]InsufficientResource, 0, 4)
allowedPodNumber := nodeInfo.Allocatable.AllowedPodNumber
if len(nodeInfo.Pods)+1 > allowedPodNumber {
insufficientResources = append(insufficientResources, InsufficientResource{
ResourceName: v1.ResourcePods,
Reason: "Too many pods",
Requested: 1,
Used: int64(len(nodeInfo.Pods)),
Capacity: int64(allowedPodNumber),
})
}
if podRequest.MilliCPU == 0 &&
podRequest.Memory == 0 &&
podRequest.EphemeralStorage == 0 &&
len(podRequest.ScalarResources) == 0 {
return insufficientResources
}
if podRequest.MilliCPU > (nodeInfo.Allocatable.MilliCPU - nodeInfo.Requested.MilliCPU) {
insufficientResources = append(insufficientResources, InsufficientResource{
ResourceName: v1.ResourceCPU,
Reason: "Insufficient cpu",
Requested: podRequest.MilliCPU,
Used: nodeInfo.Requested.MilliCPU,
Capacity: nodeInfo.Allocatable.MilliCPU,
})
}
if podRequest.Memory > (nodeInfo.Allocatable.Memory - nodeInfo.Requested.Memory) {
insufficientResources = append(insufficientResources, InsufficientResource{
ResourceName: v1.ResourceMemory,
Reason: "Insufficient memory",
Requested: podRequest.Memory,
Used: nodeInfo.Requested.Memory,
Capacity: nodeInfo.Allocatable.Memory,
})
}
if podRequest.EphemeralStorage > (nodeInfo.Allocatable.EphemeralStorage - nodeInfo.Requested.EphemeralStorage) {
insufficientResources = append(insufficientResources, InsufficientResource{
ResourceName: v1.ResourceEphemeralStorage,
Reason: "Insufficient ephemeral-storage",
Requested: podRequest.EphemeralStorage,
Used: nodeInfo.Requested.EphemeralStorage,
Capacity: nodeInfo.Allocatable.EphemeralStorage,
})
}
for rName, rQuant := range podRequest.ScalarResources {
// Skip in case request quantity is zero
if rQuant == 0 {
continue
}
if v1helper.IsExtendedResourceName(rName) {
// If this resource is one of the extended resources that should be ignored, we will skip checking it.
// rName is guaranteed to have a slash due to API validation.
var rNamePrefix string
if ignoredResourceGroups.Len() > 0 {
rNamePrefix = strings.Split(string(rName), "/")[0]
}
if ignoredExtendedResources.Has(string(rName)) || ignoredResourceGroups.Has(rNamePrefix) {
continue
}
}
if rQuant > (nodeInfo.Allocatable.ScalarResources[rName] - nodeInfo.Requested.ScalarResources[rName]) {
insufficientResources = append(insufficientResources, InsufficientResource{
ResourceName: rName,
Reason: fmt.Sprintf("Insufficient %v", rName),
Requested: podRequest.ScalarResources[rName],
Used: nodeInfo.Requested.ScalarResources[rName],
Capacity: nodeInfo.Allocatable.ScalarResources[rName],
})
}
}
return insufficientResources
}
VolumeRestrictions
NodeVolumeLimits
VolumeBinding
VolumeZone
PodTopologySpread
pkg/scheduler/framework/plugins/podtopologyspread/filtering.go
// Filter invoked at the filter extension point.
func (pl *PodTopologySpread) Filter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
node := nodeInfo.Node()
if node == nil {
return framework.AsStatus(fmt.Errorf("node not found"))
}
s, err := getPreFilterState(cycleState)
if err != nil {
return framework.AsStatus(err)
}
// However, "empty" preFilterState is legit which tolerates every toSchedule Pod.
if len(s.Constraints) == 0 {
return nil
}
podLabelSet := labels.Set(pod.Labels)
for _, c := range s.Constraints {
tpKey := c.TopologyKey
tpVal, ok := node.Labels[c.TopologyKey]
if !ok {
klog.V(5).InfoS("Node doesn't have required label", "node", klog.KObj(node), "label", tpKey)
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReasonNodeLabelNotMatch)
}
// judging criteria:
// 'existing matching num' + 'if self-match (1 or 0)' - 'global minimum' <= 'maxSkew'
minMatchNum, err := s.minMatchNum(tpKey, c.MinDomains, pl.enableMinDomainsInPodTopologySpread)
if err != nil {
klog.ErrorS(err, "Internal error occurred while retrieving value precalculated in PreFilter", "topologyKey", tpKey, "paths", s.TpKeyToCriticalPaths)
continue
}
selfMatchNum := 0
if c.Selector.Matches(podLabelSet) {
selfMatchNum = 1
}
pair := topologyPair{key: tpKey, value: tpVal}
matchNum := 0
if tpCount, ok := s.TpPairToMatchNum[pair]; ok {
matchNum = tpCount
}
skew := matchNum + selfMatchNum - minMatchNum
if skew > int(c.MaxSkew) {
klog.V(5).InfoS("Node failed spreadConstraint: matchNum + selfMatchNum - minMatchNum > maxSkew", "node", klog.KObj(node), "topologyKey", tpKey, "matchNum", matchNum, "selfMatchNum", selfMatchNum, "minMatchNum", minMatchNum, "maxSkew", c.MaxSkew)
return framework.NewStatus(framework.Unschedulable, ErrReasonConstraintsNotMatch)
}
}
return nil
}
InterPodAffinity
pkg/scheduler/framework/plugins/interpodaffinity/filtering.go
// Filter invoked at the filter extension point.
// It checks if a pod can be scheduled on the specified node with pod affinity/anti-affinity configuration.
func (pl *InterPodAffinity) Filter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
if nodeInfo.Node() == nil {
return framework.NewStatus(framework.Error, "node not found")
}
state, err := getPreFilterState(cycleState)
if err != nil {
return framework.AsStatus(err)
}
if !satisfyPodAffinity(state, nodeInfo) {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReasonAffinityRulesNotMatch)
}
if !satisfyPodAntiAffinity(state, nodeInfo) {
return framework.NewStatus(framework.Unschedulable, ErrReasonAntiAffinityRulesNotMatch)
}
if !satisfyExistingPodsAntiAffinity(state, nodeInfo) {
return framework.NewStatus(framework.Unschedulable, ErrReasonExistingAntiAffinityRulesNotMatch)
}
return nil
}