1.Netfilter 结构图
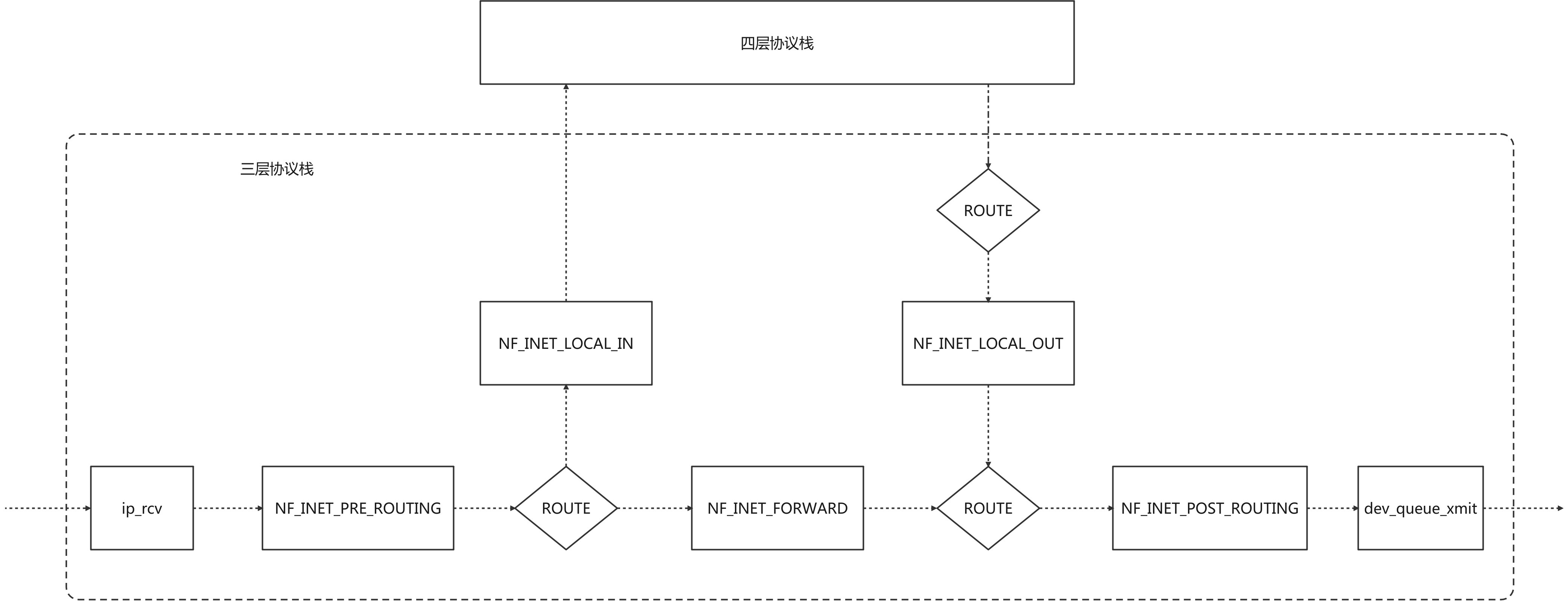
Netfilter框架的核心是五个钩子点,可以通过在钩子点注册函数,实现过滤修改数据包的功能 IPTABLES和IPVS就是通过注册钩子函数的方式来实现它们的主要功能的 ip_rcv是三层协议栈的入口函数 dev_queue_xmit最后会调用网络设备驱动发送数据包包
2.Netfilter & CONNTRACK & IPTABLES NAT 结构图
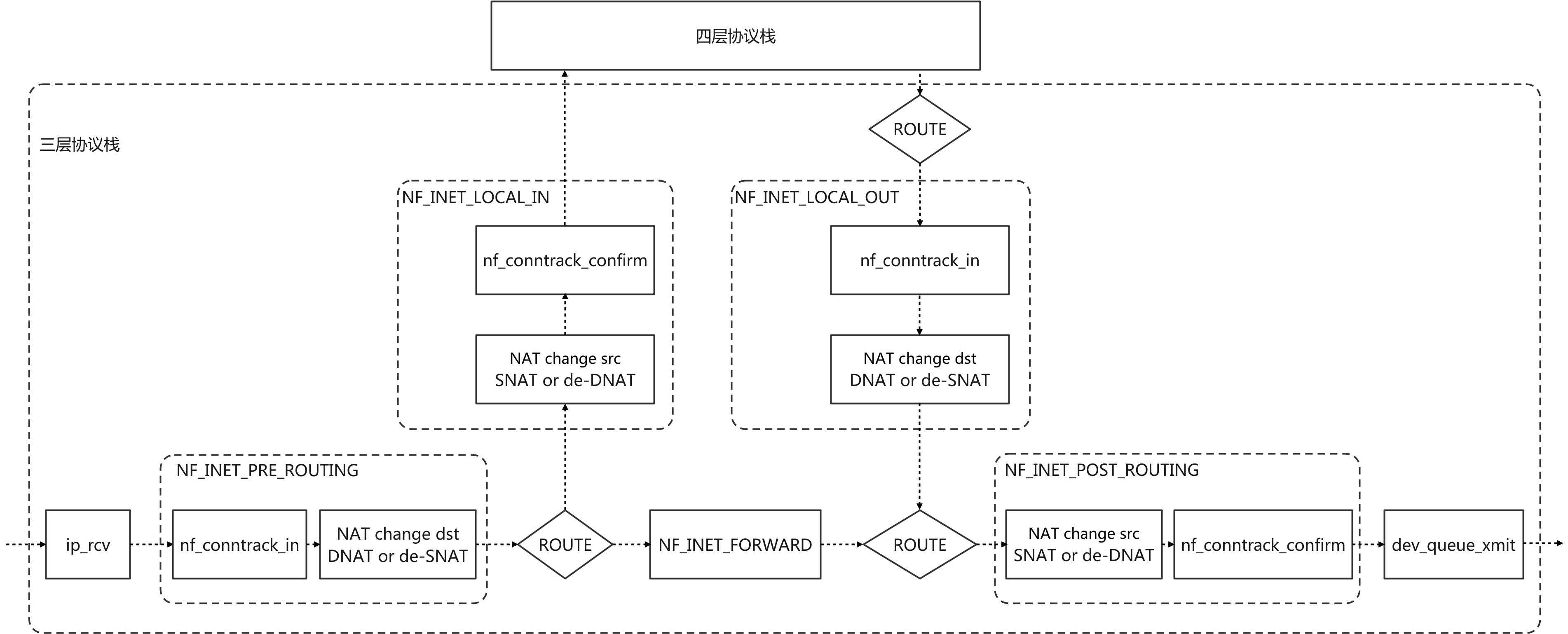
2.1 Netfilter的每个钩子点的钩子函数都有不同的优先级
/* hook函数默认优先级设置,数值越小优先级越高 */
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN, /* 最高优先级 */
NF_IP_PRI_RAW_BEFORE_DEFRAG = -450, /* 涉及IP分片重组的RAW */
NF_IP_PRI_CONNTRACK_DEFRAG = -400, /* 涉及IP分片重组的连接跟踪 */
NF_IP_PRI_RAW = -300, /* RAW表,用于取消连接跟踪 */
NF_IP_PRI_SELINUX_FIRST = -225,
NF_IP_PRI_CONNTRACK = -200, /* 连接跟踪开始 */
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100, /* NAT的改变目的地址, DNAT or de-SNAT */
NF_IP_PRI_FILTER = 0, /* IPTABLES的数据包过滤 */
NF_IP_PRI_SECURITY = 50,
NF_IP_PRI_NAT_SRC = 100, /* NAT的改变源地址, SNAT or de-DNAT */
NF_IP_PRI_SELINUX_LAST = 225,
NF_IP_PRI_CONNTRACK_HELPER = 300,
NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX, /* 连接确认 */
NF_IP_PRI_LAST = INT_MAX, /* 最低优先级 */
};
优先级CONNTRACK > DNAT > FILTER > SNAT > CONNTRACK_CONFIRM
3.CONNTRACK
3.1 conntrack注册的钩子
static const struct nf_hook_ops ipv4_conntrack_ops[] = {
{
.hook = ipv4_conntrack_in, /* return nf_conntrack_in */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_CONNTRACK,
},
{
.hook = ipv4_conntrack_local, /* return nf_conntrack_in */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_CONNTRACK,
},
{
.hook = ipv4_confirm, /* 调用nf_conntrack_confirm */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
{
.hook = ipv4_confirm, /* 调用nf_conntrack_confirm */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
};
3.2 nf_conntrack_in
nf_conntrack_in是conntrack的核心函数,主要作用是:
- 获取数据包所对应的连接,如果没有则新建连接记录
- 获取连接或者新建连接后,更新连接状态,设置skb->_nfct字段保存数据包的所属连接指针和连接的状态
所有没有标注UNCONNTRACK的数据包在nf_conntrack_in中会获取所属连接,为后续做NAT提供基础
3.2.1 nf_conntrack_in源码分析:
unsigned int
nf_conntrack_in(struct sk_buff *skb, const struct nf_hook_state *state)
{
enum ip_conntrack_info ctinfo;
struct nf_conn *ct, *tmpl;
u_int8_t protonum;
int dataoff, ret;
/* 先尝试获取从skb->_nfct字段获取连接指针和连接状态
* skb->_nfct是unsigned long类型,后3位保存连接状态,其余位保存连接记录的指针.
* 内核经常用这种操作节省内存 */
tmpl = nf_ct_get(skb, &ctinfo);
/* 如果成功获取到了连接的指针和状态,或者数据包标注取消连接跟踪 */
if (tmpl || ctinfo == IP_CT_UNTRACKED) {
/* Previously seen (loopback or untracked)? Ignore. */
/* 三种包会到这里
* 1.已经获取了连接的skb
* 2.不进行连接跟踪的skb
* 3.设置了模板连接的skb */
if ((tmpl && !nf_ct_is_template(tmpl)) ||
ctinfo == IP_CT_UNTRACKED) {
/* 已经获取连接和不进行连接跟踪的skb在增加命名空间ignore计数后返回ACCEPT */
NF_CT_STAT_INC_ATOMIC(state->net, ignore);
return NF_ACCEPT;
}
/* 模板连接的skb会走到这里,skb的_nfct字段会被重置
* 但是tmpl已经获取到了模板连接和连接状态信息 */
skb->_nfct = 0;
}
/* 没有连接的skb和设置了模板连接的skb会继续走 */
/* rcu_read_lock()ed by nf_hook_thresh */
/* 获取skb四层协议头偏移 */
dataoff = get_l4proto(skb, skb_network_offset(skb), state->pf, &protonum);
if (dataoff <= 0) {
pr_debug("not prepared to track yet or error occurred\n");
NF_CT_STAT_INC_ATOMIC(state->net, error);
NF_CT_STAT_INC_ATOMIC(state->net, invalid);
ret = NF_ACCEPT;
goto out;
}
/* ICMP协议相关,暂时不看 */
if (protonum == IPPROTO_ICMP || protonum == IPPROTO_ICMPV6) {
ret = nf_conntrack_handle_icmp(tmpl, skb, dataoff,
protonum, state);
if (ret <= 0) {
ret = -ret;
goto out;
}
/* ICMP[v6] protocol trackers may assign one conntrack. */
if (skb->_nfct)
goto out;
}
repeat:
/* nf_conntrack_in的核心函数,作用如下
* 1.根据skb的五元组在全局哈希表中匹配连接
* 2.没有匹配到连接的话会新建连接
* 3.匹配或建立连接后,更新连接状态
* 4.将连接指针和连接状态保存到skb->_nfct字段 */
ret = resolve_normal_ct(tmpl, skb, dataoff,
protonum, state);
if (ret < 0) {
/* Too stressed to deal. */
NF_CT_STAT_INC_ATOMIC(state->net, drop);
ret = NF_DROP;
goto out;
}
/* 到这里skb的连接已经被确认了,重新获取连接指针和连接状态 */
ct = nf_ct_get(skb, &ctinfo);
if (!ct) {
/* Not valid part of a connection */
NF_CT_STAT_INC_ATOMIC(state->net, invalid);
ret = NF_ACCEPT;
goto out;
}
/* 四层协议连接跟踪,例如tcp连接状态的改变 */
ret = nf_conntrack_handle_packet(ct, skb, dataoff, ctinfo, state);
if (ret <= 0) {
/* Invalid: inverse of the return code tells
* the netfilter core what to do */
pr_debug("nf_conntrack_in: Can't track with proto module\n");
nf_conntrack_put(&ct->ct_general);
skb->_nfct = 0;
NF_CT_STAT_INC_ATOMIC(state->net, invalid);
if (ret == -NF_DROP)
NF_CT_STAT_INC_ATOMIC(state->net, drop);
/* Special case: TCP tracker reports an attempt to reopen a
* closed/aborted connection. We have to go back and create a
* fresh conntrack.
*/
if (ret == -NF_REPEAT)
goto repeat;
ret = -ret;
goto out;
}
if (ctinfo == IP_CT_ESTABLISHED_REPLY &&
!test_and_set_bit(IPS_SEEN_REPLY_BIT, &ct->status))
nf_conntrack_event_cache(IPCT_REPLY, ct);
out:
if (tmpl)
nf_ct_put(tmpl);
return ret;
}
3.2.2 init_conntrack是conntrack新建连接的函数,源码分析:
/* Allocate a new conntrack: we return -ENOMEM if classification
failed due to stress. Otherwise it really is unclassifiable. */
static noinline struct nf_conntrack_tuple_hash *
init_conntrack(struct net *net, struct nf_conn *tmpl,
const struct nf_conntrack_tuple *tuple,
struct sk_buff *skb,
unsigned int dataoff, u32 hash)
{
struct nf_conn *ct;
struct nf_conn_help *help;
struct nf_conntrack_tuple repl_tuple;
struct nf_conntrack_ecache *ecache;
struct nf_conntrack_expect *exp = NULL;
const struct nf_conntrack_zone *zone;
struct nf_conn_timeout *timeout_ext;
struct nf_conntrack_zone tmp;
/* 翻转数据包的五元组获取回包的五元组 */
if (!nf_ct_invert_tuple(&repl_tuple, tuple)) {
pr_debug("Can't invert tuple.\n");
return NULL;
}
/* 模板连接设置的zone */
zone = nf_ct_zone_tmpl(tmpl, skb, &tmp);
/* 根据命名空间,zone,原始五元组和回包五元组新建连接ct */
ct = __nf_conntrack_alloc(net, zone, tuple, &repl_tuple, GFP_ATOMIC,
hash);
if (IS_ERR(ct))
return (struct nf_conntrack_tuple_hash *)ct;
/* synproxy相关 */
if (!nf_ct_add_synproxy(ct, tmpl)) {
nf_conntrack_free(ct);
return ERR_PTR(-ENOMEM);
}
timeout_ext = tmpl ? nf_ct_timeout_find(tmpl) : NULL;
if (timeout_ext)
nf_ct_timeout_ext_add(ct, rcu_dereference(timeout_ext->timeout),
GFP_ATOMIC);
nf_ct_acct_ext_add(ct, GFP_ATOMIC);
nf_ct_tstamp_ext_add(ct, GFP_ATOMIC);
nf_ct_labels_ext_add(ct);
ecache = tmpl ? nf_ct_ecache_find(tmpl) : NULL;
nf_ct_ecache_ext_add(ct, ecache ? ecache->ctmask : 0,
ecache ? ecache->expmask : 0,
GFP_ATOMIC);
/* 期望子连接,很少的协议会有(例如ftp协议) */
local_bh_disable();
if (net->ct.expect_count) {
spin_lock(&nf_conntrack_expect_lock);
exp = nf_ct_find_expectation(net, zone, tuple);
if (exp) {
pr_debug("expectation arrives ct=%p exp=%p\n",
ct, exp);
/* Welcome, Mr. Bond. We've been expecting you... */
__set_bit(IPS_EXPECTED_BIT, &ct->status);
/* exp->master safe, refcnt bumped in nf_ct_find_expectation */
ct->master = exp->master;
if (exp->helper) {
help = nf_ct_helper_ext_add(ct, GFP_ATOMIC);
if (help)
rcu_assign_pointer(help->helper, exp->helper);
}
#ifdef CONFIG_NF_CONNTRACK_MARK
ct->mark = exp->master->mark;
#endif
#ifdef CONFIG_NF_CONNTRACK_SECMARK
ct->secmark = exp->master->secmark;
#endif
NF_CT_STAT_INC(net, expect_new);
}
spin_unlock(&nf_conntrack_expect_lock);
}
if (!exp)
__nf_ct_try_assign_helper(ct, tmpl, GFP_ATOMIC);
/* Now it is inserted into the unconfirmed list, bump refcount */
/* 统计计数,然后将连接的原始五元组插入cpu的未确认链表中 */
nf_conntrack_get(&ct->ct_general);
nf_ct_add_to_unconfirmed_list(ct);
local_bh_enable();
if (exp) {
if (exp->expectfn)
exp->expectfn(ct, exp);
nf_ct_expect_put(exp);
}
return &ct->tuplehash[IP_CT_DIR_ORIGINAL];
}
3.2.3 CONNTRACK的连接记录有两个五元组
- 第一个是初始方向的五元组
- 第二个是期望回包的五元组
这两个五元组在nf_conntrack_confirm中会被插入到同一个全局哈希表中,nf_conntrack_in中通过查找全局哈希表来确认数据包所属的连接 nf_conntrack_in新建的连接的两个五元组不会立即添加到全局哈希表中,而是先将初始方向五元组插入未确认链表. nf_conntrack_in新建的连接经过nf_conntrack_confirm之后它的两个五元组才会被插入全局哈希表中 这种先建立后确认机制的原因是: 数据包可能在Netfilter途中就被内核丢弃(比如filter表),同时只有在数据包经历一个完整的netfilter的NAT过程后,连接才被确认,后续连接的两个方向的数据包不会在去匹配规则,而是直接根据连接记录进行NAT 连接跟踪在三层协议栈入口位置PRE_ROUTING和LOCAL_OUT注册了调用nf_conntrack_in钩子函数,确保所有数据包的连接能够被记录 连接跟踪在三层协议栈出口位置POST_ROUTING和LOCAL_IN注册了调用nf_conntrack_confirm钩子函数,确保新建的连接能够被确认
3.3 nf_conntrack_confirm
3.3.1 nf_conntrack_confirm源码分析:
/* Confirm a connection: returns NF_DROP if packet must be dropped. */
static inline int nf_conntrack_confirm(struct sk_buff *skb)
{
/* 从skb中获取_nfct字段得到数据包所属连接的指针 */
struct nf_conn *ct = (struct nf_conn *)skb_nfct(skb);
int ret = NF_ACCEPT;
/* 获取到了数据包的所属连接 */
if (ct) {
/* 为没被确认的连接进行确认 */
if (!nf_ct_is_confirmed(ct))
ret = __nf_conntrack_confirm(skb);
if (likely(ret == NF_ACCEPT))
nf_ct_deliver_cached_events(ct);
}
/* 没有所属连接的skb包直接返回ACCEPT */
return ret;
}
/* Confirm a connection given skb; places it in hash table */
int
__nf_conntrack_confirm(struct sk_buff *skb)
{
const struct nf_conntrack_zone *zone;
unsigned int hash, reply_hash;
struct nf_conntrack_tuple_hash *h;
struct nf_conn *ct;
struct nf_conn_help *help;
struct nf_conn_tstamp *tstamp;
struct hlist_nulls_node *n;
enum ip_conntrack_info ctinfo;
struct net *net;
unsigned int sequence;
int ret = NF_DROP;
/* 从skb中获取连接指针和连接状态 */
ct = nf_ct_get(skb, &ctinfo);
net = nf_ct_net(ct);
/* ipt_REJECT uses nf_conntrack_attach to attach related
ICMP/TCP RST packets in other direction. Actual packet
which created connection will be IP_CT_NEW or for an
expected connection, IP_CT_RELATED. */
if (CTINFO2DIR(ctinfo) != IP_CT_DIR_ORIGINAL)
return NF_ACCEPT;
/* 获取数据包zone */
zone = nf_ct_zone(ct);
local_bh_disable();
/* 获取原始五元组和回包五元组的hash */
do {
sequence = read_seqcount_begin(&nf_conntrack_generation);
/* reuse the hash saved before */
hash = *(unsigned long *)&ct->tuplehash[IP_CT_DIR_REPLY].hnnode.pprev;
hash = scale_hash(hash);
reply_hash = hash_conntrack(net,
&ct->tuplehash[IP_CT_DIR_REPLY].tuple);
} while (nf_conntrack_double_lock(net, hash, reply_hash, sequence));
/* We're not in hash table, and we refuse to set up related
* connections for unconfirmed conns. But packet copies and
* REJECT will give spurious warnings here.
*/
/* Another skb with the same unconfirmed conntrack may
* win the race. This may happen for bridge(br_flood)
* or broadcast/multicast packets do skb_clone with
* unconfirmed conntrack.
*/
if (unlikely(nf_ct_is_confirmed(ct))) {
WARN_ON_ONCE(1);
nf_conntrack_double_unlock(hash, reply_hash);
local_bh_enable();
return NF_DROP;
}
pr_debug("Confirming conntrack %p\n", ct);
/* We have to check the DYING flag after unlink to prevent
* a race against nf_ct_get_next_corpse() possibly called from
* user context, else we insert an already 'dead' hash, blocking
* further use of that particular connection -JM.
*/
nf_ct_del_from_dying_or_unconfirmed_list(ct);
if (unlikely(nf_ct_is_dying(ct))) {
nf_ct_add_to_dying_list(ct);
goto dying;
}
/* See if there's one in the list already, including reverse:
NAT could have grabbed it without realizing, since we're
not in the hash. If there is, we lost race. */
hlist_nulls_for_each_entry(h, n, &nf_conntrack_hash[hash], hnnode)
if (nf_ct_key_equal(h, &ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple,
zone, net))
goto out;
hlist_nulls_for_each_entry(h, n, &nf_conntrack_hash[reply_hash], hnnode)
if (nf_ct_key_equal(h, &ct->tuplehash[IP_CT_DIR_REPLY].tuple,
zone, net))
goto out;
/* Timer relative to confirmation time, not original
setting time, otherwise we'd get timer wrap in
weird delay cases. */
ct->timeout += nfct_time_stamp;
atomic_inc(&ct->ct_general.use);
/* 标识连接已确定 */
ct->status |= IPS_CONFIRMED;
/* set conntrack timestamp, if enabled. */
tstamp = nf_conn_tstamp_find(ct);
if (tstamp)
tstamp->start = ktime_get_real_ns();
/* Since the lookup is lockless, hash insertion must be done after
* starting the timer and setting the CONFIRMED bit. The RCU barriers
* guarantee that no other CPU can find the conntrack before the above
* stores are visible.
*/
/* 将连接的原始五元组和回包五元组插入全局哈希表中 */
__nf_conntrack_hash_insert(ct, hash, reply_hash);
nf_conntrack_double_unlock(hash, reply_hash);
local_bh_enable();
help = nfct_help(ct);
if (help && help->helper)
nf_conntrack_event_cache(IPCT_HELPER, ct);
nf_conntrack_event_cache(master_ct(ct) ?
IPCT_RELATED : IPCT_NEW, ct);
return NF_ACCEPT;
out:
nf_ct_add_to_dying_list(ct);
ret = nf_ct_resolve_clash(net, skb, ctinfo, h);
dying:
nf_conntrack_double_unlock(hash, reply_hash);
NF_CT_STAT_INC(net, insert_failed);
local_bh_enable();
return ret;
}
4.IPTABLES NAT
IPTABLES的NAT依赖于连接跟踪,对于没有连接跟踪的数据包不做NAT处理
4.1 NAT注册的钩子
static const struct nf_hook_ops nf_nat_ipv4_ops[] = {
/* 三层协议栈入口位置,在包过滤之前,修改目的地址(DNAT or de-SNAT) */
{
.hook = nf_nat_ipv4_in, /* 首先调用nf_nat_ipv4_fn */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_NAT_DST,
},
/* 三层协议栈出口位置,包过滤之后,修改源地址(SNAT or de-DNAT) */
{
.hook = nf_nat_ipv4_out, /* 首先调用nf_nat_ipv4_fn */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_NAT_SRC,
},
/* 三层协议栈入口位置,包过滤之前,修改目的地址(DNAT or de-SNAT) */
{
.hook = nf_nat_ipv4_local_fn, /* 首先调用nf_nat_ipv4_fn */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_NAT_DST,
},
/* 三层协议栈出口位置,包过滤之后,修改源地址(SNAT or de-DNAT) */
{
.hook = nf_nat_ipv4_fn, /* nf_nat_ipv4_fn */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_NAT_SRC,
},
};
4.2 nf_nat_ipv4_fn
NAT注册的钩子函数都会先调用nf_nat_ipv4_fn 函数nf_nat_ipv4_fn中会先获取数据包的conntrack连接指针和连接状态,没有conntrack的连接,就不会进行NAT
4.2.1 nf_nat_ipv4_fn源码分析:
static unsigned int
nf_nat_ipv4_fn(void *priv, struct sk_buff *skb,
const struct nf_hook_state *state)
{
struct nf_conn *ct;
enum ip_conntrack_info ctinfo;
/* 先从skb的_nfct字段获取连接指针和连接状态,如果没有则直接返回,不做NAT处理 */
ct = nf_ct_get(skb, &ctinfo);
if (!ct)
return NF_ACCEPT;
/* ICMP协议相关 */
if (ctinfo == IP_CT_RELATED || ctinfo == IP_CT_RELATED_REPLY) {
if (ip_hdr(skb)->protocol == IPPROTO_ICMP) {
if (!nf_nat_icmp_reply_translation(skb, ct, ctinfo,
state->hook))
return NF_DROP;
else
return NF_ACCEPT;
}
}
/* 调用核心函数nf_nat_inet_fn */
return nf_nat_inet_fn(priv, skb, state);
}
unsigned int
nf_nat_inet_fn(void *priv, struct sk_buff *skb,
const struct nf_hook_state *state)
{
struct nf_conn *ct;
enum ip_conntrack_info ctinfo;
struct nf_conn_nat *nat;
/* maniptype == SRC for postrouting. */
enum nf_nat_manip_type maniptype = HOOK2MANIP(state->hook);
/* 再获取一遍skb包的连接指针和连接状态 */
ct = nf_ct_get(skb, &ctinfo);
/* Can't track? It's not due to stress, or conntrack would
* have dropped it. Hence it's the user's responsibilty to
* packet filter it out, or implement conntrack/NAT for that
* protocol. 8) --RR
*/
if (!ct)
return NF_ACCEPT;
/* 获取Natwork Namespace */
nat = nfct_nat(ct);
/* 根据连接状态做不同处理 */
switch (ctinfo) {
case IP_CT_RELATED:
case IP_CT_RELATED_REPLY:
/* Only ICMPs can be IP_CT_IS_REPLY. Fallthrough */
case IP_CT_NEW:
/* Seen it before? This can happen for loopback, retrans,
* or local packets.
*/
if (!nf_nat_initialized(ct, maniptype)) {
struct nf_nat_lookup_hook_priv *lpriv = priv;
/* 获取NAT表自己保存的钩子函数入口 */
struct nf_hook_entries *e = rcu_dereference(lpriv->entries);
unsigned int ret;
int i;
if (!e)
goto null_bind;
/* 执行入口保存的所有钩子函数,nat表的hook函数会顺序遍历规则 */
for (i = 0; i < e->num_hook_entries; i++) {
ret = e->hooks[i].hook(e->hooks[i].priv, skb,
state);
if (ret != NF_ACCEPT)
return ret;
if (nf_nat_initialized(ct, maniptype))
goto do_nat;
}
null_bind:
ret = nf_nat_alloc_null_binding(ct, state->hook);
if (ret != NF_ACCEPT)
return ret;
} else {
pr_debug("Already setup manip %s for ct %p (status bits 0x%lx)\n",
maniptype == NF_NAT_MANIP_SRC ? "SRC" : "DST",
ct, ct->status);
if (nf_nat_oif_changed(state->hook, ctinfo, nat,
state->out))
goto oif_changed;
}
break;
default:
/* ESTABLISHED */
WARN_ON(ctinfo != IP_CT_ESTABLISHED &&
ctinfo != IP_CT_ESTABLISHED_REPLY);
if (nf_nat_oif_changed(state->hook, ctinfo, nat, state->out))
goto oif_changed;
}
do_nat:
/* 根据连接记录对数据包进行nat处理 */
return nf_nat_packet(ct, ctinfo, state->hook, skb);
oif_changed:
nf_ct_kill_acct(ct, ctinfo, skb);
return NF_DROP;
}
/* Do packet manipulations according to nf_nat_setup_info. */
unsigned int nf_nat_packet(struct nf_conn *ct,
enum ip_conntrack_info ctinfo,
unsigned int hooknum,
struct sk_buff *skb)
{
enum nf_nat_manip_type mtype = HOOK2MANIP(hooknum);
enum ip_conntrack_dir dir = CTINFO2DIR(ctinfo);
unsigned int verdict = NF_ACCEPT;
unsigned long statusbit;
if (mtype == NF_NAT_MANIP_SRC)
statusbit = IPS_SRC_NAT;1
else
statusbit = IPS_DST_NAT;10
/* 回包异或取反 */
/* Invert if this is reply dir. */
if (dir == IP_CT_DIR_REPLY)
statusbit ^= IPS_NAT_MASK;11
/* Non-atomic: these bits don't change. */
if (ct->status & statusbit)
/* NAT修改数据包 */
verdict = nf_nat_manip_pkt(skb, ct, mtype, dir);
return verdict;
}
unsigned int nf_nat_manip_pkt(struct sk_buff *skb, struct nf_conn *ct,
enum nf_nat_manip_type mtype,
enum ip_conntrack_dir dir)
{
struct nf_conntrack_tuple target;
/* We are aiming to look like inverse of other direction. */
/* 原始包根据回复五元组NAT,回包根据原始五元组de-NAT */
nf_ct_invert_tuple(&target, &ct->tuplehash[!dir].tuple);
switch (target.src.l3num) {
case NFPROTO_IPV6:
if (nf_nat_ipv6_manip_pkt(skb, 0, &target, mtype))
return NF_ACCEPT;
break;
case NFPROTO_IPV4:
if (nf_nat_ipv4_manip_pkt(skb, 0, &target, mtype))
return NF_ACCEPT;
break;
default:
WARN_ON_ONCE(1);
break;
}
return NF_DROP;
}
static bool nf_nat_ipv4_manip_pkt(struct sk_buff *skb,
unsigned int iphdroff,
const struct nf_conntrack_tuple *target,
enum nf_nat_manip_type maniptype)
{
struct iphdr *iph;
unsigned int hdroff;
/* skb可写 */
if (skb_ensure_writable(skb, iphdroff + sizeof(*iph)))
return false;
/* IP头 */
iph = (void *)skb->data + iphdroff;
hdroff = iphdroff + iph->ihl * 4;
/* 四层端口修改 */
if (!l4proto_manip_pkt(skb, iphdroff, hdroff, target, maniptype))
return false;
iph = (void *)skb->data + iphdroff;
/* NAT */
if (maniptype == NF_NAT_MANIP_SRC) {
csum_replace4(&iph->check, iph->saddr, target->src.u3.ip);
iph->saddr = target->src.u3.ip;
} else {
csum_replace4(&iph->check, iph->daddr, target->dst.u3.ip);
iph->daddr = target->dst.u3.ip;
}
return true;
}