基于linux内核5.4.54 昨天分享了veth的原理: veth原理—-两个容器通过veth通信时数据包的收发路径 一般情况容器直接不会通过veth直接通信,会通过docker0网桥通信 今天分析容器通过veth和docker0网桥的通信路径
单机容器网络结构
在宿主机上通过docker创建两个容器时会自动生成如图所示的网络结构
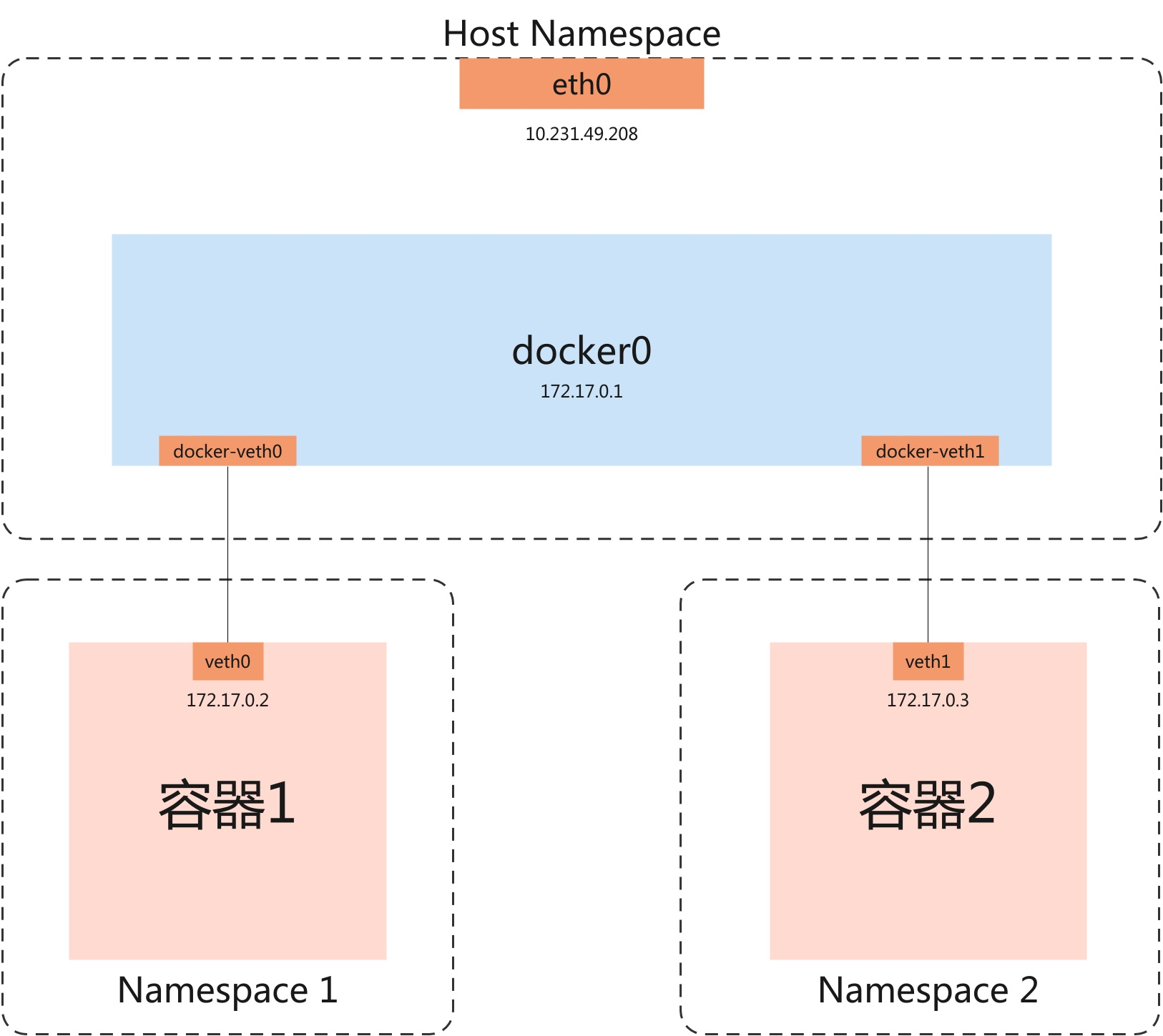
- 在宿主机上会生成一个docker0网桥
- 容器1和docker0网桥之间通过veth相连,容器2一样
简单看一下Namespace
网络设备的Namespace:
网络设备注册时,会通过net_device->nd_net(网络设备结构体字段)设置Net Namespace。
分析结构图设备的Namespace:
-
veth0属于Namespace1;veth1属于Namespace2;
-
eth0,docker0,docker0上的两个veth设备属于Host Namespace
数据包的Namespace:
数据包的Namespace由skb_buff->dev->nd_net(数据包目的设备的Namespace)决定
进程的Namespace:
通过clone()创建进程时会通过task_struct->nsproxy(进程结构体字段)为进程设置Namespace,nsproxy->net_ns决定进程的Net Namespace
/* nsproxy结构体 其中包含了各种命名空间隔离和Cgroup,以后有时间会多了解 */
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct cgroup_namespace *cgroup_ns;
};
Socket套接字的Namespace
进程创建Socket时,会设置sock->sk_net为current->nsproxy->net_ns,即将当前进程的Net Namespace传递给sock套接字。
分析两种情况
###1. 容器1通过网桥向容器2发送数据包
####收发路径:
进程(容器1)
|--通过socket系统调用进入内核,经过的是Namespace1的网络协议栈
kernel层: 创建skb结构体,从用户空间拷贝数据到内核空间
TCP/UDP封包
IP封包,跑Namespace1的路由和netfilter
|--出协议栈进入网络设备
调用网络设备驱动的传输数据包函数
|
veth_xmit: veth驱动注册的传输函数
|
veth_forward_skb
|
__dev_forward_skb: 清除 skb 中可能影响命名空间隔离的所有信息
| 并且会更新数据包要到的网络设备(skb->dev),由veth0改为docker-veth0
| 数据包要跑的协议栈(network namespace)由skb->dev的nd_net字段决定
|
XDP钩子点
|
netif_rx
|
netif_rx_internal: cpu软中断负载均衡
|
enqueue_to_backlog: 将skb包加入指定cpu的input_pkt_queue队尾
queue为空时激活网络软中断,
queue不为空不需要激活软中断,cpu没清空队列之前
会自动触发软中断
每个cpu都有自己的input_pkt_queue(接收队列,默认大小1000,可修改),和process_queue(处理队列),软中断处理函数处理完成process_queue中的所有skb包之后,会将将input_pkt_queue拼接到process_queue
input_pkt_queue和process_queue是cpu为非NAPI设备准备的队列,NAPI设备有自己的队列
一直到这里,数据包路径和veth文档中的两个veth通信的发送阶段是完全一致的,docker0网桥处理数据包主要在__netif_receive_skb_core中
cpu处理网络数据包过程:
do_softirq()
|
net_rx_action: 网络软中断处理函数
|
napi_poll
|
n->poll: 调用目的网络设备驱动的poll函数
| veth设备没有定义poll,调用默认poll函数-process_backlog
|
process_backlog: cpu循环从process_queue中取出skb处理,最多处理300个skb,
| 处理队列清空后,拼接input_pkt_queue到process_queue队尾
|
__netif_receive_skb
|
...
|
__netif_receive_skb_core
数据包处理代码分析:
/*
* __netif_receive_skb_core代码分析
* 代码做了很多删减,剩下了网桥的处理和数据包传递给上层处理的部分
* 其他很多部分例如vlan,xdp,tcpdump等代码删去了
*/
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc,
struct packet_type **ppt_prev)
{
struct packet_type *ptype, *pt_prev;
rx_handler_func_t *rx_handler;
struct sk_buff *skb = *pskb;
struct net_device *orig_dev;
bool deliver_exact = false;
int ret = NET_RX_DROP;
__be16 type;
/* 记录skb包目的设备 */
orig_dev = skb->dev;
/* 设置skb包的协议头指针 */
skb_reset_network_header(skb);
if (!skb_transport_header_was_set(skb))
skb_reset_transport_header(skb);
skb_reset_mac_len(skb);
pt_prev = NULL;
another_round:
...
/**
* skb包的目的设备是docker-veth0,veth作为了bridge的一个接口
* docker-veth0在注册时会设置rx_handler为网桥的收包函数br_handle_frame
* 黄色处代码为调用bridge的br_handle_frame
*/
rx_handler = rcu_dereference(skb->dev->rx_handler);
if (rx_handler) {
...
switch (rx_handler(&skb)) {
case RX_HANDLER_CONSUMED: /* 已处理,无需进一步处理 */
ret = NET_RX_SUCCESS;
goto out;
case RX_HANDLER_ANOTHER: /* 再处理一次 */
goto another_round;
case RX_HANDLER_EXACT: /* 精确传递到ptype->dev == skb->dev */
deliver_exact = true;
case RX_HANDLER_PASS:
break;
default:
BUG();
}
}
...
/* 获取三层协议 */
type = skb->protocol;
/*
* 调用指定协议的协议处理函数(例如ip_rcv函数) 把数据包传递给上层协议层处理
* ip_rcv函数是网络协议栈的入口函数
* 数据包到达这里会经过netfilter,路由,最后被转发或者发给上层协议栈
*/
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&orig_dev->ptype_specific);
...
if (pt_prev) {
if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC)))
goto drop;
*ppt_prev = pt_prev;
} else {
drop:
if (!deliver_exact)
atomic_long_inc(&skb->dev->rx_dropped);
else
atomic_long_inc(&skb->dev->rx_nohandler);
kfree_skb(skb);
ret = NET_RX_DROP;
}
out:
*pskb = skb;
return ret;
}
网桥处理代码分析:
/* br_handle_frame,已删减 */
rx_handler_result_t br_handle_frame(struct sk_buff **pskb)
{
struct net_bridge_port *p;
struct sk_buff *skb = *pskb;
const unsigned char *dest = eth_hdr(skb)->h_dest;
...
forward:
switch (p->state) {
case BR_STATE_FORWARDING:
case BR_STATE_LEARNING:
/* 目的地址是否是设备链路层地址 */
if (ether_addr_equal(p->br->dev->dev_addr, dest))
skb->pkt_type = PACKET_HOST;
return nf_hook_bridge_pre(skb, pskb);
default:
drop:
kfree_skb(skb);
}
return RX_HANDLER_CONSUMED;
}
nf_hook_bridge_pre
|
br_handle_frame_finish
/* br_handle_frame_finish,已删减 */
int br_handle_frame_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_bridge_port *p = br_port_get_rcu(skb->dev);
enum br_pkt_type pkt_type = BR_PKT_UNICAST;
struct net_bridge_fdb_entry *dst = NULL;
struct net_bridge_mdb_entry *mdst;
bool local_rcv, mcast_hit = false;
struct net_bridge *br;
u16 vid = 0;
...
if (dst) {
unsigned long now = jiffies;
/* 如果目的地是宿主机 */
if (dst->is_local)
/*
* 这个函数回修改skb->dev为网桥设备,然后回到__netif_receive_skb_core
* 把skb送上Host Net Namespace的三层协议栈处理
*/
return br_pass_frame_up(skb);
if (now != dst->used)
dst->used = now;
/*
* 目的地不是宿主机把数据包转发到指定端口
* 代码实现是调用目的端口设备驱动的数据包接收函数
* 这次路径是调用docker-veth1的veth_xmit
* 上文分析了veth_xmit,会修改数据包目的设备
* 从docker-veth1修改为veth1,然后送到cpu队列等待处理
* cpu处理数据包时,跑veth1(也就是Namespace2)的网络协议栈
* 最后容器2进程收包
*/
br_forward(dst->dst, skb, local_rcv, false);
}
...
out:
return 0;
drop:
kfree_skb(skb);
goto out;
}
总结路径:
容器1进程生成数据包
|
通过Namespace1协议栈送到veth0
|
veth0驱动改skb目的设备为docker-veth0,送skb到cpu队列
|
cpu处理数据包,因为docker-veth0是网桥的一个端口,调用网桥收包函数
|
网桥修改skb目的设备为docker-veth1,调用docker-veth1驱动
|
docker-veth1驱动改skb目的设备为veth1,送skb到cpu队列
|
cpu处理数据包调用veth1的收包驱动函数,送上veth1(Namespace2)的网络协议栈
|
容器2进程收包
2. 容器1通过网桥向宿主机发送数据包
代码前面都分析过了,直接总结
总结路径:
容器1进程生成数据包
|
通过Namespace1协议栈送到veth0
|
veth0驱动改skb目的设备为docker-veth0,送skb到cpu队列
|
cpu处理数据包,因为docker-veth0是网桥的一个端口,调用网桥收包函数
|
网桥判断目的地为宿主机,修改skb目的设备为bridge,
然后跑宿主机(Host Namespace)三层协议栈